总字符数: 33.62K
代码: 18.08K, 文本: 7.33K
预计阅读时间: 1.84 小时
Splunk索引数据类型
在计算机科学和数据库领域,索引(Index)是一种数据结构,用于提高数据库表中数据的检索速度.索引可以看作是一本书的目录,它允许用户快速找到所需的信息,而不必扫描整个数据集.
索引的主要特点和作用:
- 提高查询速度:索引通过创建一个指向数据行的指针列表,使得数据库引擎能够快速定位到特定的数据行,从而大大加快查询操作的速度.
- 减少磁盘I/O:索引可以减少数据库系统需要读取的磁盘页数,因为索引通常存储在内存中,或者存储在磁盘上更紧凑的区域,从而减少了磁盘I/O操作.
- 唯一性约束:索引可以强制列的唯一性,确保表中的数据没有重复值.例如,主键索引就是一种唯一索引.
- 排序:索引可以自动对数据进行排序,这对于需要排序的查询非常有用.
- 加速连接操作:在多表连接查询中,索引可以显著提高连接操作的性能.
索引的类型:
- B-Tree索引:最常见的索引类型,适用于范围查询和排序操作.
- 哈希索引:适用于等值查询,但不支持范围查询.
- 全文索引:用于文本搜索,支持复杂的文本匹配查询.
- 空间索引:用于地理空间数据,支持空间操作.
Splunk平台可以索引任何类型的数据.特别是Splunk平台可以索引任何和所有IT流、机器和历史数据,如Microsoft Windows事件日志、Web服务器日志、实时应用程序日志、网络流量、指标、更改监控、消息队列、存档文件等.
由于Splunk Enterprise是本机部署的,因此可以直接将数据导入实例,也可以使用通用或重型转发器来导入数据.一般来说,可以将Splunk Enterprise输入分类如下:
- Files and directories —> 文件和目录
- Network events —> 网络事件
- Windows data —> Windows数据
- Other sources —> 其他来源
文件和目录
使用文件和目录监视器输入处理器从文件和目录中获取数据.要监视文件和目录,请参阅从文件和目录获取数据.
网络事件
索引来自任何网络端口的数据,例如来自sysystem-ng或通过TCP协议传输的任何其他应用程序的远程数据.它还可以索引UDP数据,但尽可能使用TCP以增强可靠性.
Splunk Enterprise还可以接收和索引远程设备发出的SNMP事件和警报.
要从网络端口获取数据,请参阅从TCP和UDP端口获取数据.
要获取SNMP数据,请参阅将SNMP事件发送到Splunk部署.
Windows数据
Splunk Enterprise的Windows版本直接接受各种Windows特定的输入.使用Splunk Web可以配置以下Windows特定的输入类型:
- Windows Event Log data —> Windows事件日志数据
- Windows Registry data —> Windows注册表数据
- Windows Management Instrumentation (WMI) data
- Active Directory data —>Active Directory数据
- Performance monitoring data —> 性能监控数据
Other sources 其他来源
Splunk Enterprise可以直接收集以下数据源:
- 使用HTTP事件收集器直接从具有HTTP或HTTPS协议的源获取数据.请参阅HTTP事件收集器端点
- 从技术基础设施、安全系统和业务应用程序中获取指标数据.请参阅Metrics
- 监视先进先出(FIFO)队列.请参阅监控先进先出(FIFO)队列
- 从API和其他远程数据接口以及消息队列获取数据.请参阅脚本输入
- 定义自定义输入功能来扩展Splunk Enterprise框架.请参阅Splunk开发者门户上的为Splunk Cloud Platform或Splunk Enterprise创建自定义数据输入
导入索引数据
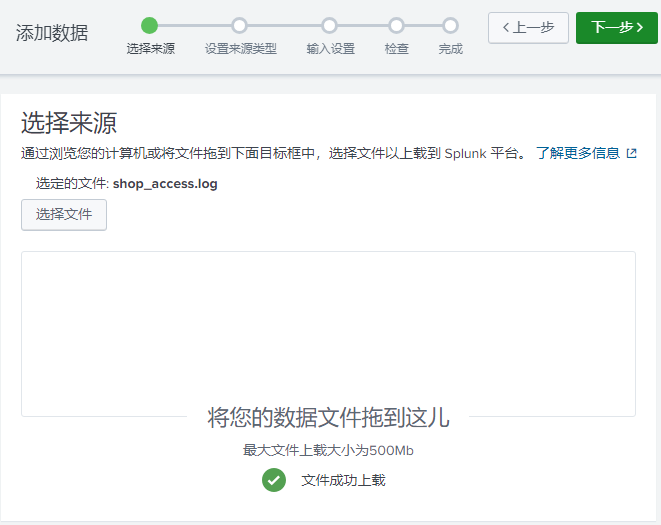
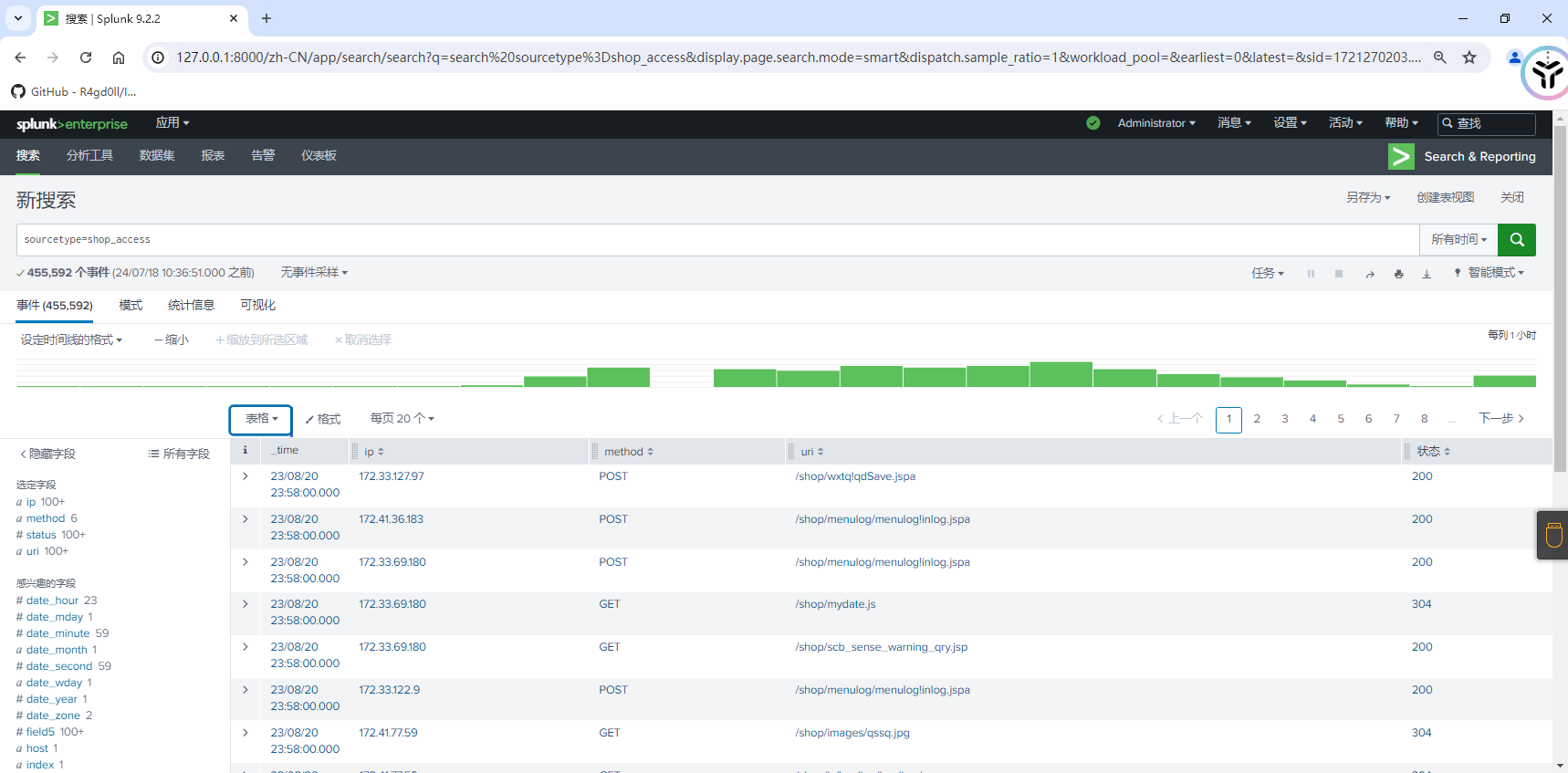
示例:shop_access.log
导入数据—>点击下一步

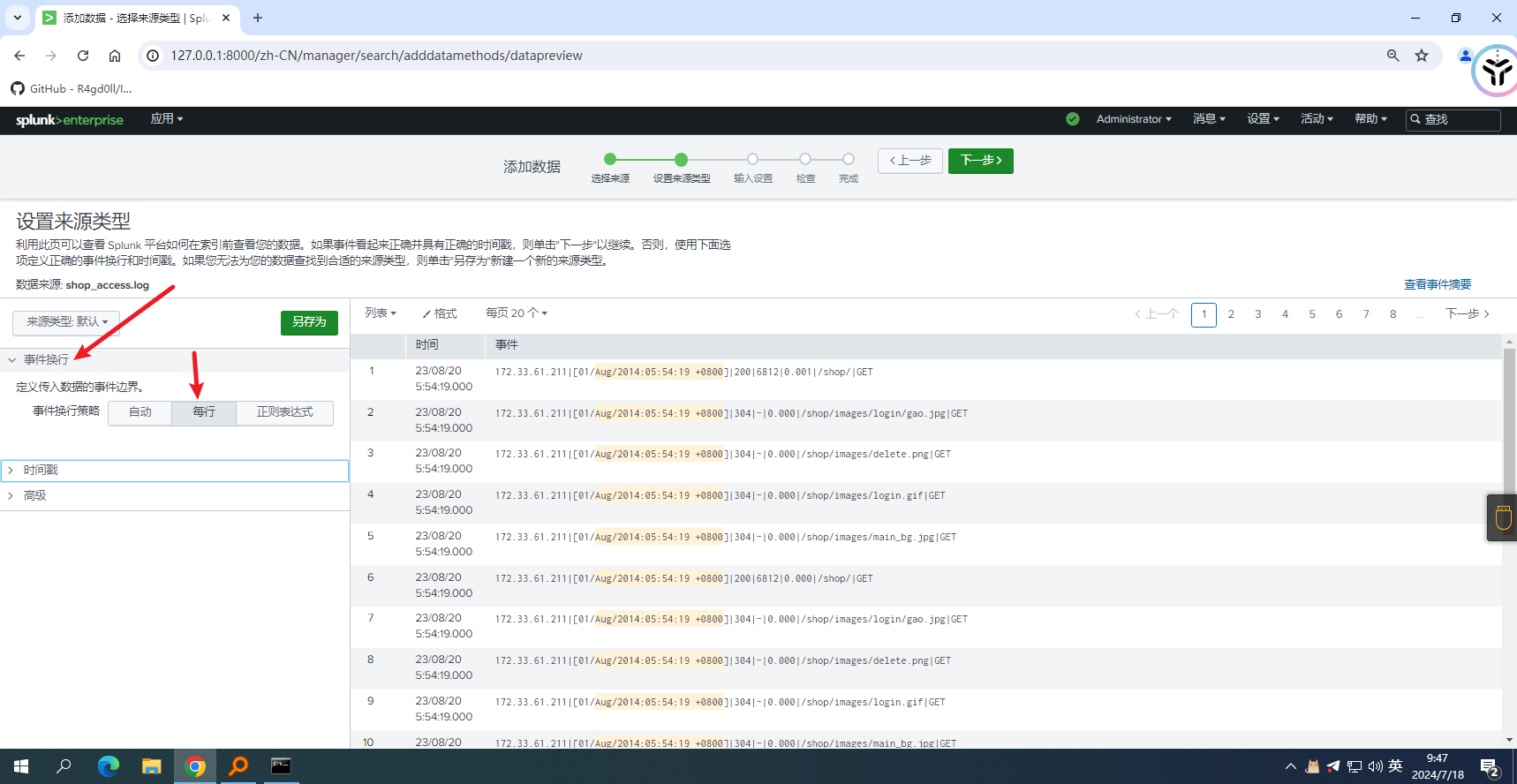
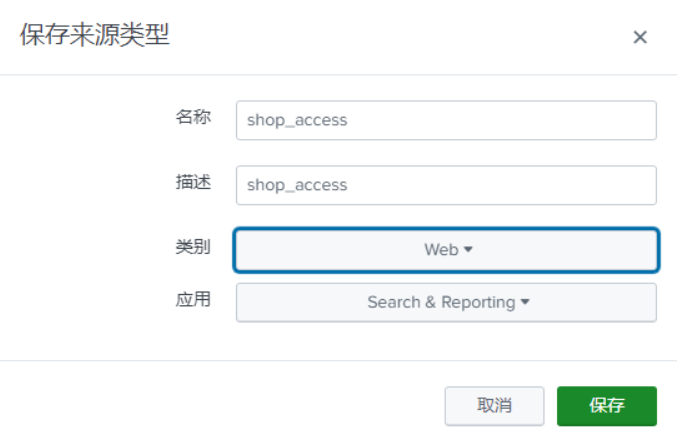
点击—>下一步,事件换行选择每行 名称及描述随便写
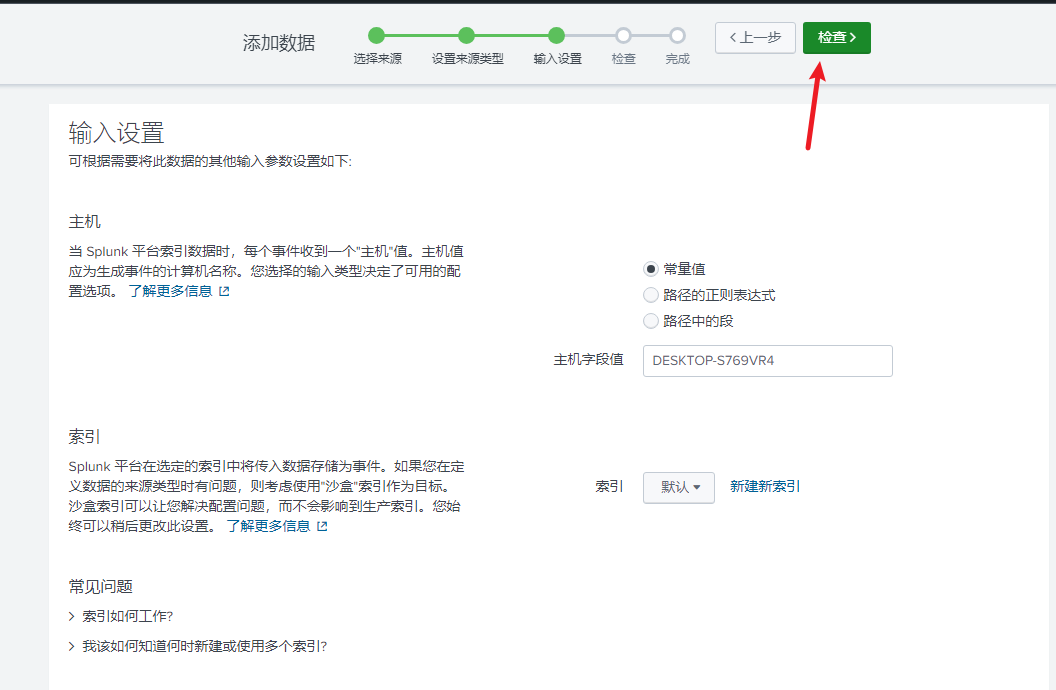
点击检查—>提交
上传成功后,点击搜索开始浏览数据叭~~~
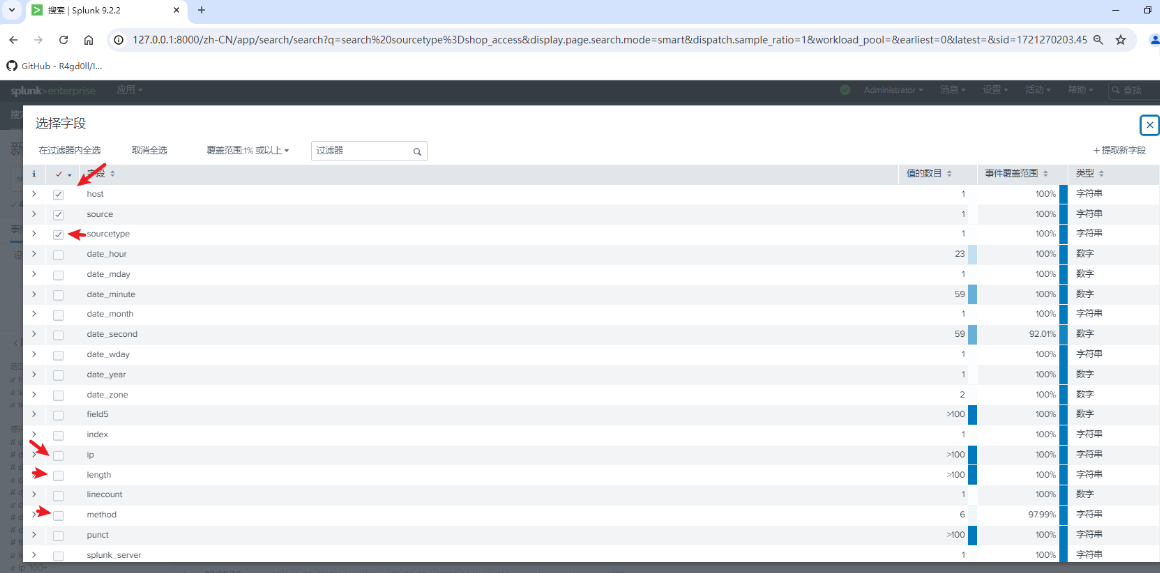
字段提取器
Splunk提供了一种非常简单的方式来提取字段,就是使用字段提取器,即使在你完全不了解正则表达式的情况下,也可以轻松完成字段提取.
执行事件搜索,左边栏往下,单击提取新字段,进入字段提取器.
在事件列表中,选择一个需要进行字段提取的示例事件–>点击该事件—>下一步.
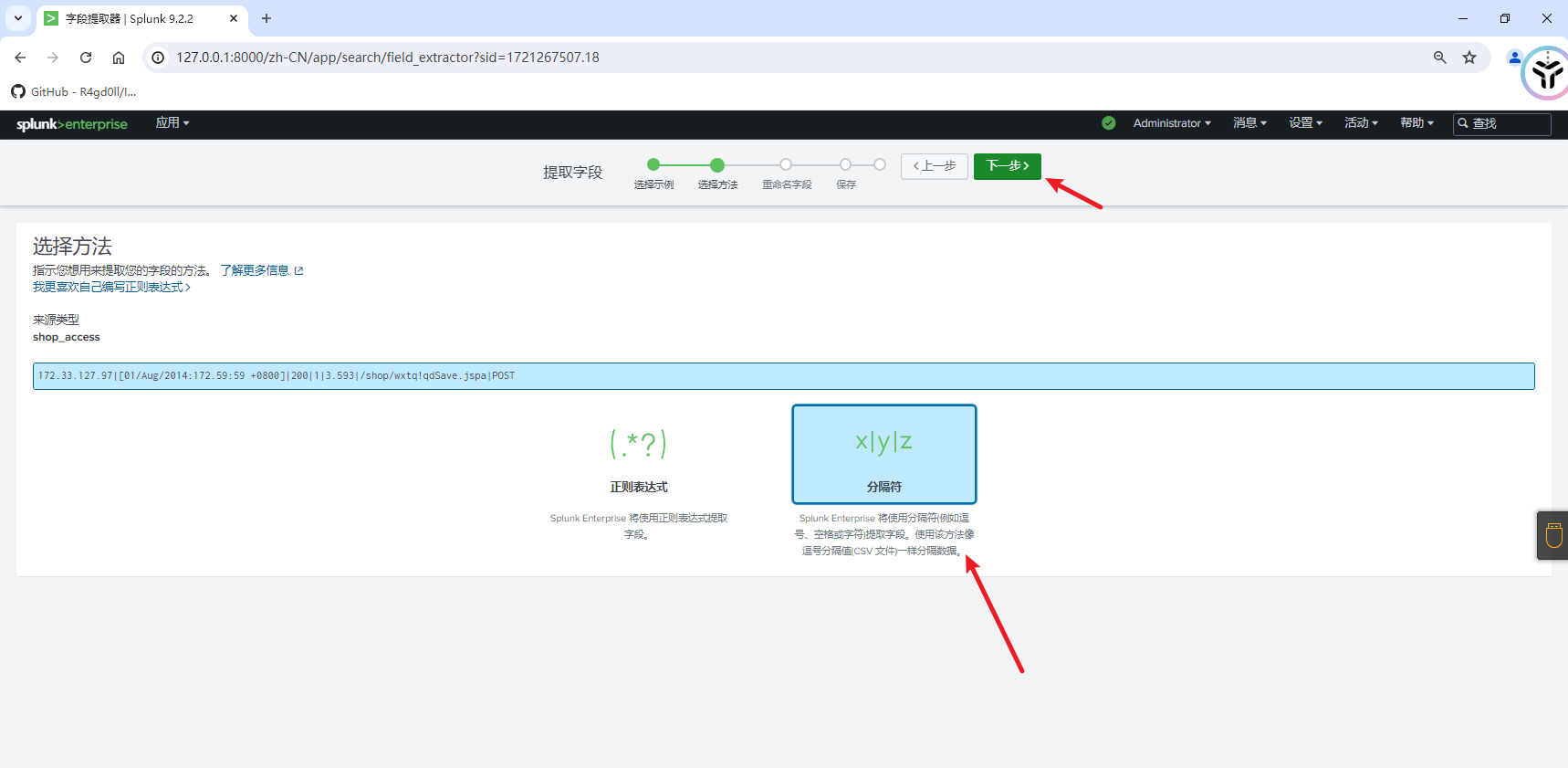
Splunk提供了两种字段提取的方法:正则表达式和分隔符.正则表达式主要用于非结构化数据;而基于表格的结构化数据,使用分隔符即可.
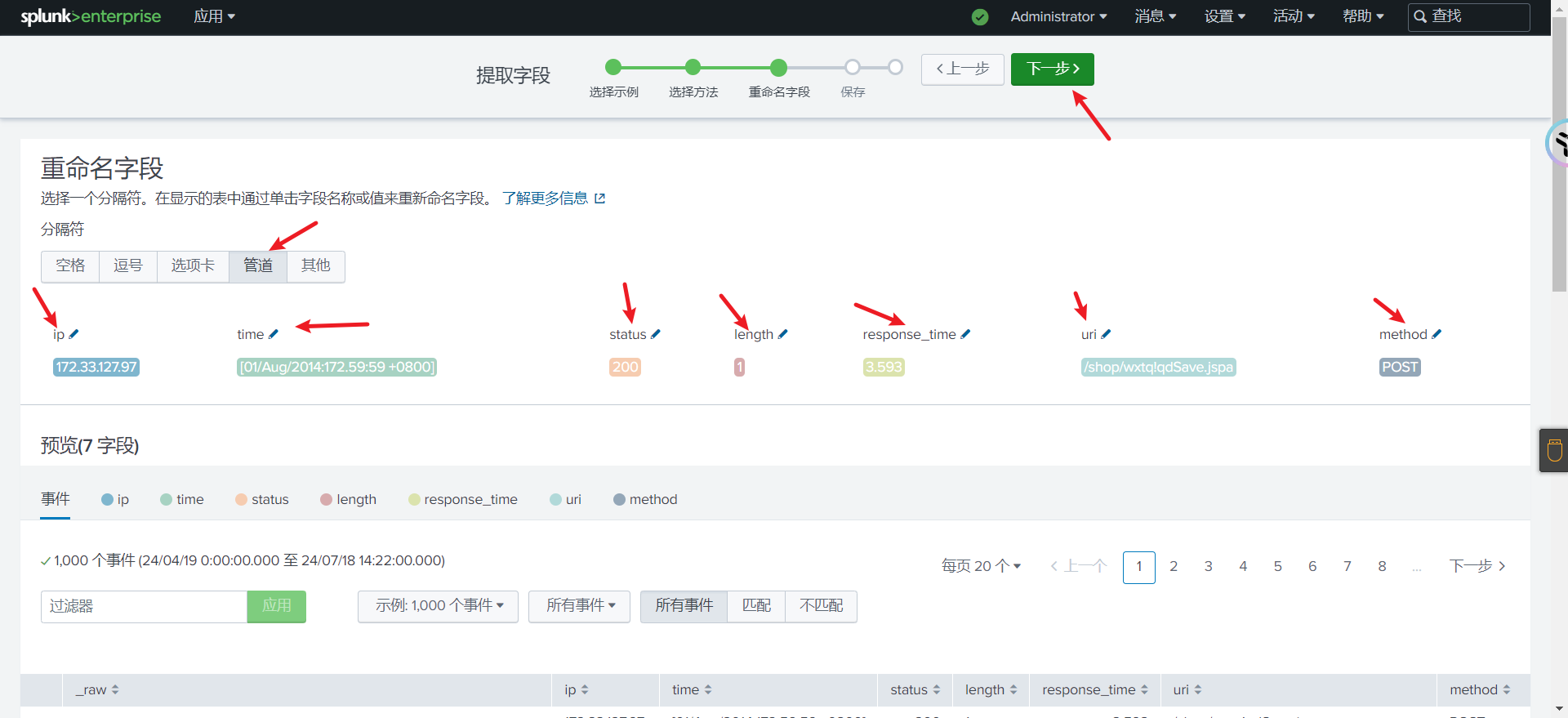
选择需要字段提取的值,下面会出现对话框,对字段名称进行命名.一般我们也可手动编辑正则表达式进行调整.
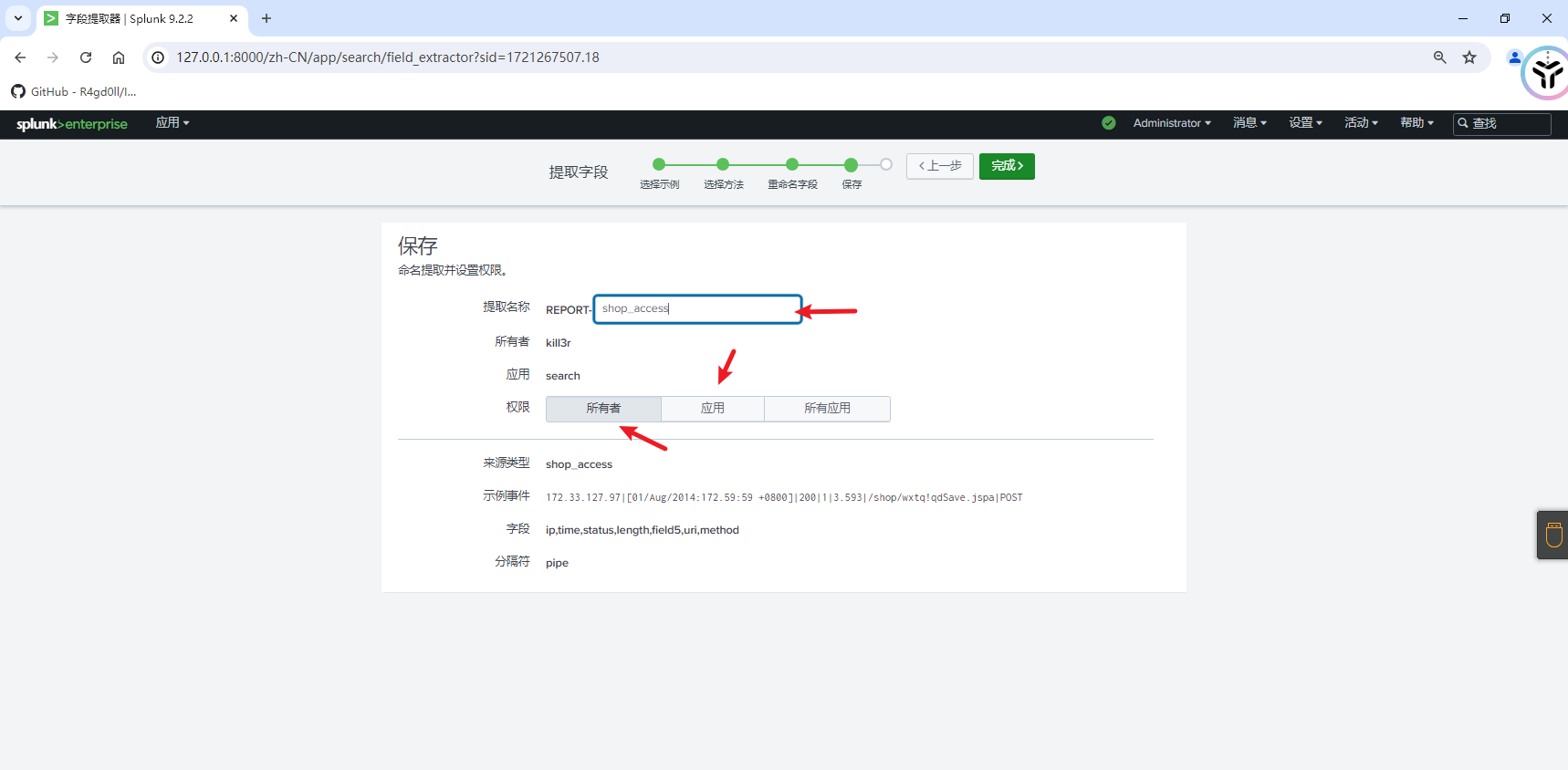
设置完成后点击下一步.可以对提取名称和权限进行设置,点击完成来保存提取.
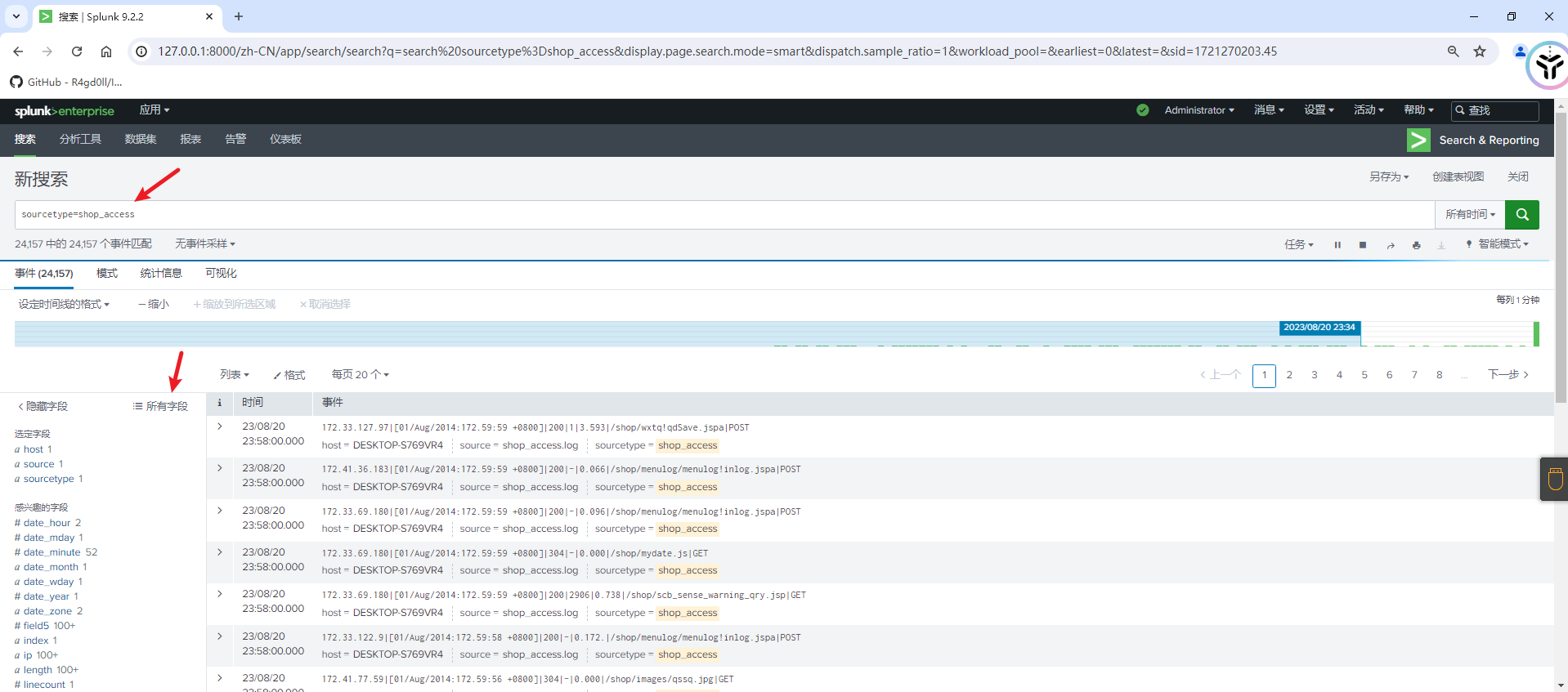
开始搜索,选择所有字段,隐藏自带的字段,选择我们新增的字段
即可看到我们新增的字段内容
正则表达式提取
secure中的相关字段1
2
3
4
5
6
7
8
9
10
11
12
13
14
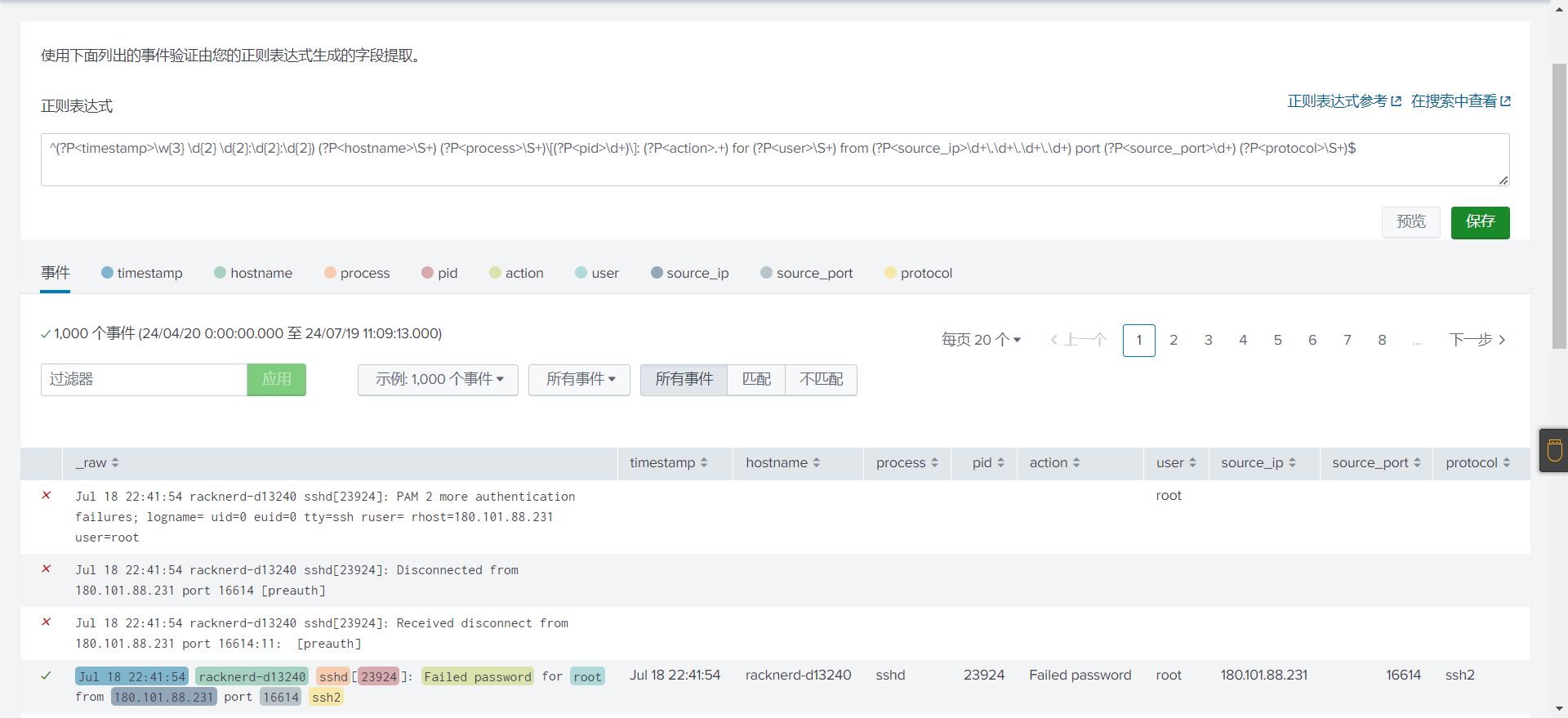
15^(?P<timestamp>\w{3} \d{2} \d{2}:\d{2}:\d{2}) (?P<hostname>\S+) (?P<process>\S+)\[(?P<pid>\d+)\]: (?P<action>.+) for (?P<user>\S+) from (?P<source_ip>\d+\.\d+\.\d+\.\d+) port (?P<source_port>\d+) (?P<protocol>\S+)$
# (?P<name>...)命名
# \S+: 匹配一个或多个非空白字符
# \d+: 匹配一个或多个数字
# .+: 匹配任意字符(包括空格)
# ^(?P<timestamp>\w{3} \d{2} \d{2}:\d{2}:\d{2}) # 匹配时间戳部分,格式为 "MMM DD HH:MM:SS"
# (?P<hostname>\S+) # 匹配主机名,非空白字符
# (?P<process>\S+) # 匹配进程名,非空白字符
# \[(?P<pid>\d+)\]: # 匹配进程 ID,在方括号内,包含一个或多个数字
# (?P<action>.+) # 匹配动作,包含一个或多个任意字符(贪婪匹配)
# for (?P<user>\S+) # 匹配 "for" 后面的用户名,非空白字符
# from (?P<source_ip>\d+\.\d+\.\d+\.\d+) # 匹配源 IP 地址,格式为四个由点分隔的数字
# port (?P<source_port>\d+) # 匹配源端口号,包含一个或多个数字
# (?P<protocol>\S+)$ # 匹配协议,非空白字符,行结束
搜索命令
基本搜索与过滤命令
search
使用 search 命令可以从索引中检索事件或过滤先前搜索结果.它可以使用关键字、带引号的短语、通配符和字段值表达式来查找事件.
- 隐含使用:在任何搜索的开头,
search命令是隐含的,你无需显式地写它. - 过滤结果:你可以在搜索中使用
search命令来过滤管道中上一个命令的结果.
通过检索事件后,你可以使用其他命令进行转换、筛选和报告.使用竖线(|)或管道字符将这些命令链接到检索到的事件.
search 命令支持使用CIDR表示法的IPv4和IPv6地址以及IP地址.
1 | # 语法 |
逻辑表达式
1 | # 比较表达式 |
索引表达式
1 | 语法: "<字符串>" | <术语> | <搜索修饰符> |
时间表达式
1 | 语法: [<时间格式>] (<时间修饰符>)... |
当搜索是搜索中的第一个命令时,您可以使用关键字、短语、字段、布尔表达式和比较表达式等术语来精确指定要从 Splunk 索引中检索哪些事件.如果您没有指定字段,搜索会在 _raw 字段中查找这些术语.
一些搜索术语的例子包括:
- 关键字:
error login == error AND login - 引用的短语:
"database error" - 布尔运算符:
login NOT (error OR fail) - 通配符:
fail* - 字段-值对:
status=404, status!=404, 或 status>200
转义
在使用搜索命令时,如果短语或字段值中包含空格、逗号、管道、引号或括号,你需要用引号将它们括起来.引号必须是成对出现的.例如:
- 搜索
error | stats count会统计包含“error”这个词的事件数量. - 搜索
... | search "error | stats count"会返回包含error、|、stats和count按顺序出现的事件.
如果你想把某些关键字当作普通的字符串对待,而不是它们的默认含义,比如布尔运算符或特定的字段/值对,你也需要用引号把它们括起来.例如:
- 搜索
error "AND"会查找包含AND这个词的事件. - 搜索
error "startswith=foo"会查找包含startswith=foo这个短语的事件.
反斜杠(\)可以用来转义特殊字符,比如引号、管道和反斜杠本身.例如:
\"会被当作字符串引号.\\会被当作字符串反斜杠.\|会被当作字符串管道.
示例
比较两个字段
1
source="shop_access.log" | where fieldsA=fieldsB
对于不相等的比较,您可以通过多种方式指定条件.
1
2source="shop_access.log" | where fieldA!=fieldB
source="shop_access.log" | where NOT fieldA=fieldB使用IN运算符进行多个字段值比较
1
2
3
4
5source="shop_access.log" | status IN(200,301,302,500)
# 包含字符
source="shop_access.log" | status IN(error,warning)
# NOT运算符与IN运算符一起使用
source="shop_access.log" | NOT clientip IN (211.166.11.101, 182.236.164.11, 128.241.220.82)CIDR匹配
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
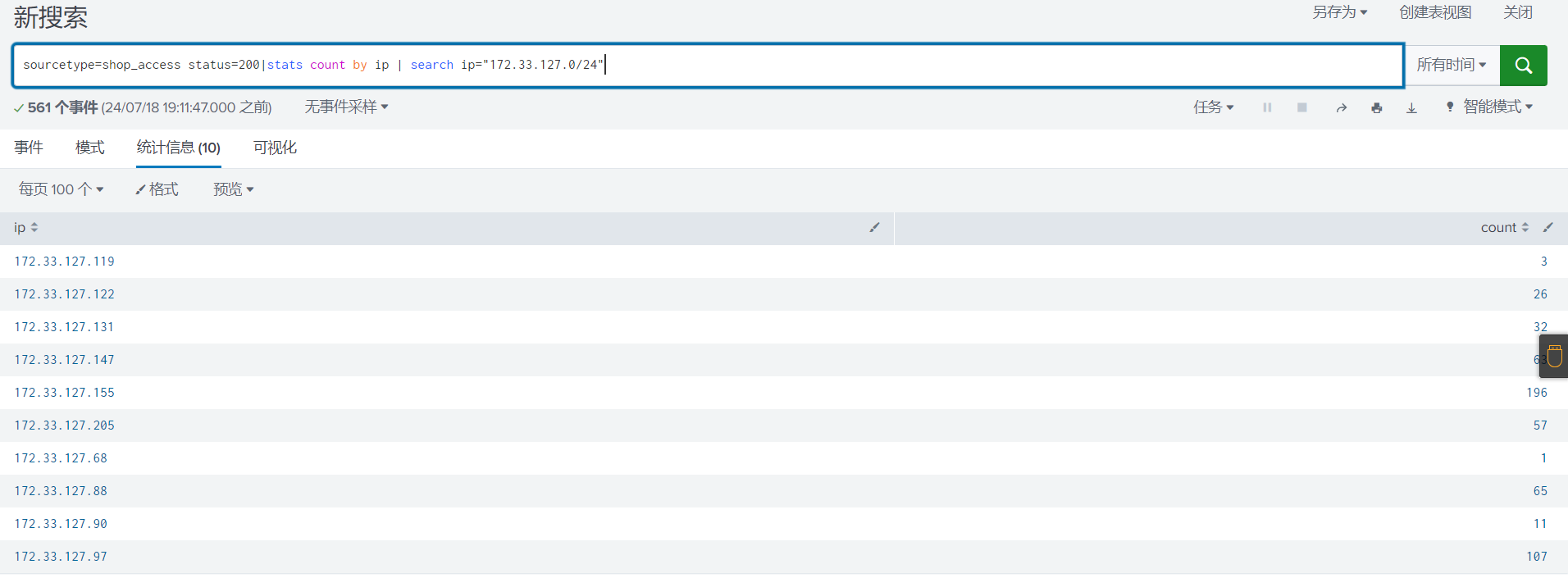
27search 命令可以对包含IPv4和IPv6地址的字段执行CIDR匹配.
# 假设 ip 字段包含以下值:
172.32.162.49
172.32.172.59
172.32.172.84
172.32.229.172
172.33.114.186
172.33.117.114
172.33.117.18
172.33.117.38
172.33.117.63
172.33.117.97
172.33.118.158
172.33.127.119
172.33.127.122
172.33.127.131
172.33.127.147
172.33.127.155
172.33.127.172
172.33.127.205
172.33.127.68
172.33.127.88
172.33.127.90
172.33.127.97
source="shop_access.log" status=200 | stats count by ip | search ip="172.33.127.0/24"字段值对匹配
1
2# 源IP等于10.9.165.* 或者 目的IP等于10.9.165.8
src="10.9.165.*" OR dst="10.9.165.8"使用布尔运算符和比较运算符
1
2
3source="shop_access.log" (status=200 OR status=304) ip!="172.33.127.97"
# 或
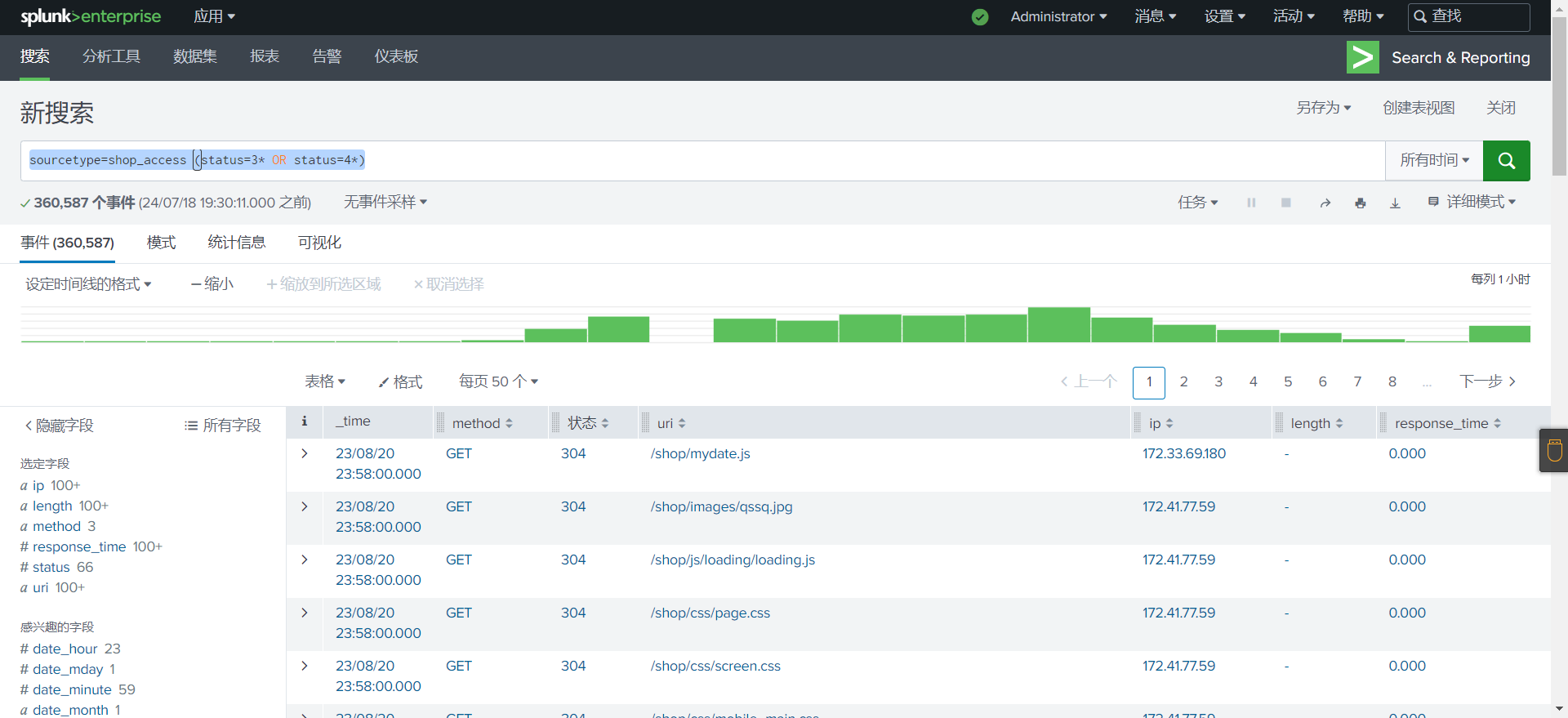
source="shop_access.log" status IN(200,304) ip!="172.33.127.97"使用通配符
1
2
3source="shop_access.log" (status=3* OR status=4*)
# 或
source="shop_access.log" status IN(4*, 5*)
fields
根据字段列表条件保留或删除搜索结果中的字段.
默认情况下,内部字段 _raw 和 _time 包含在Splunk Web的输出中.使用 outputcsv 命令可以在输出中包含其他内部字段.参见用法.
1 | # 语法 |
示例
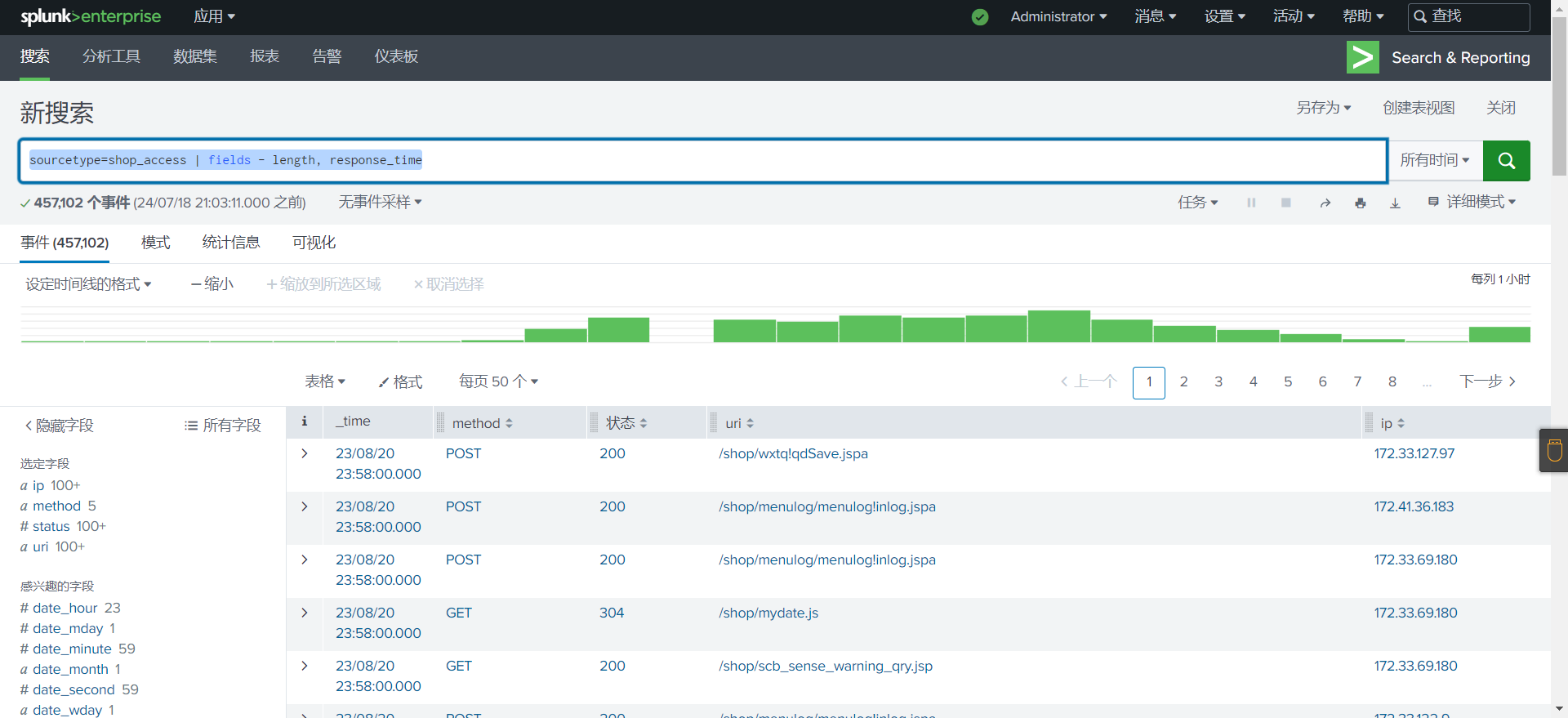
从结果中删除
length和response_time字段1
source="shop_access.log" | fields - length, response_time
仅保留
host和ip字段.删除所有内部字段.内部字段开始以下划线字符开头,例如_time1
source="shop_access.log" | fields length, response_time| fields - *
仅保留字段
source、sourcetype、host以及所有以error开头的字段1
source="shop_access.log" | fields source, sourcetype, host, error*
where
where 命令使用eval-expressions来过滤搜索结果.这些eval-expressions必须是布尔表达式,其中表达式返回true或false
1 | # 语法 |
Where命令使用与eval命令相同的表达式语法.此外,这两个命令都将带引号的字符串解释为文字.如果该字符串未加引号,则将其视为字段名.因此,您可以使用Where命令来比较两个不同的字段,这是search命令不能完成的.
| 命令 | 示例 | 描述 |
|---|---|---|
| where | where ipaddress=clientip |
查找字段 ipaddress 等于字段 clientip 的事件. |
| search | search host=www2 |
查找字段 host 包含字符串值 www2 的事件 |
| where | where host="www2" |
查找字段 host 中的值为字符串值 www2 的事件. |
Where并且可以像Mysql数据库那样使用Like命令来模糊匹配
like 函数允许使用百分号%作为通配符,来匹配任意数量的字符
1 | # 查找 ipaddress 字段的值以198.开始的事件 |
uniq、dedup
1 | # 描述: uniq 命令会根据事件的完整内容进行去重,如果两个事件在所有字段上的值都相同,它们将被视为重复并被移除. |
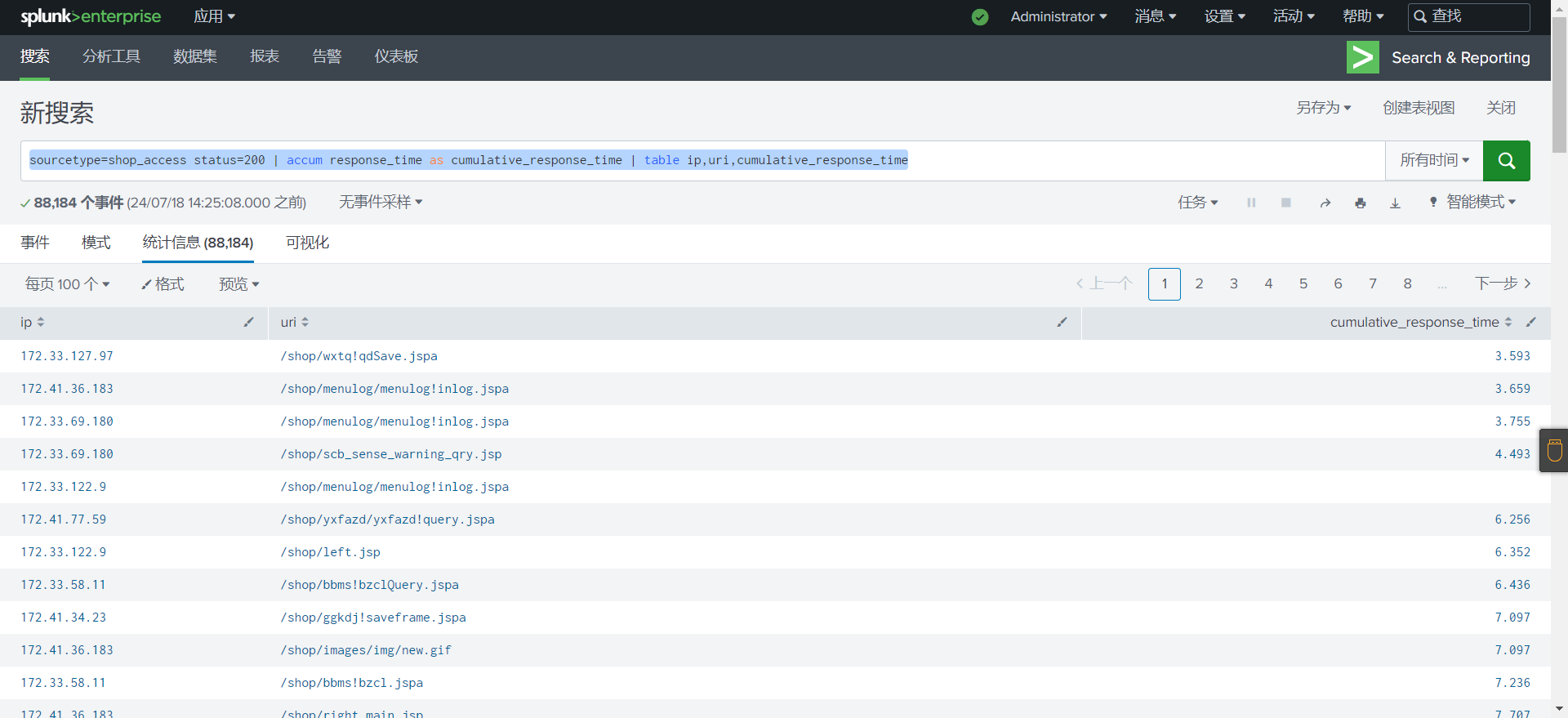
accum
对于每个事件,其中 field 是一个数字, accum 命令计算运行总数或数字之和.累计的总和可以返回到相同的字段或您指定的 newfield .
1 | # 语法 |
数据提取与转换命令
regex
eval
eval 命令能帮你计算东西并把结果放到搜索结果里.如果结果里没有指定的字段则会新建一个字段,如果结果里已经有这个字段,它会用新计算的结果替换原来的值.
eval 命令可以处理数字、文字和逻辑判断.
如果想连续用多个 eval 命令可以用逗号分割,它会按顺序执行,并且后面的命令可以用前面命令的结果.
eval和stats命令的区别 stats 命令是用来统计事件中的字段数据的,而 eval 命令则是通过已有字段和表达式来创建新字段1 | # 语法 |
示例
创建包含计算结果的新字段
1
2# 在每个事件中创建一个名为 velocity 的新字段.通过将距离字段中的值除以时间字段中的值来计算速度.
source="shop_access.log" | eval velocity=distance/time使用if函数分析字段值
1
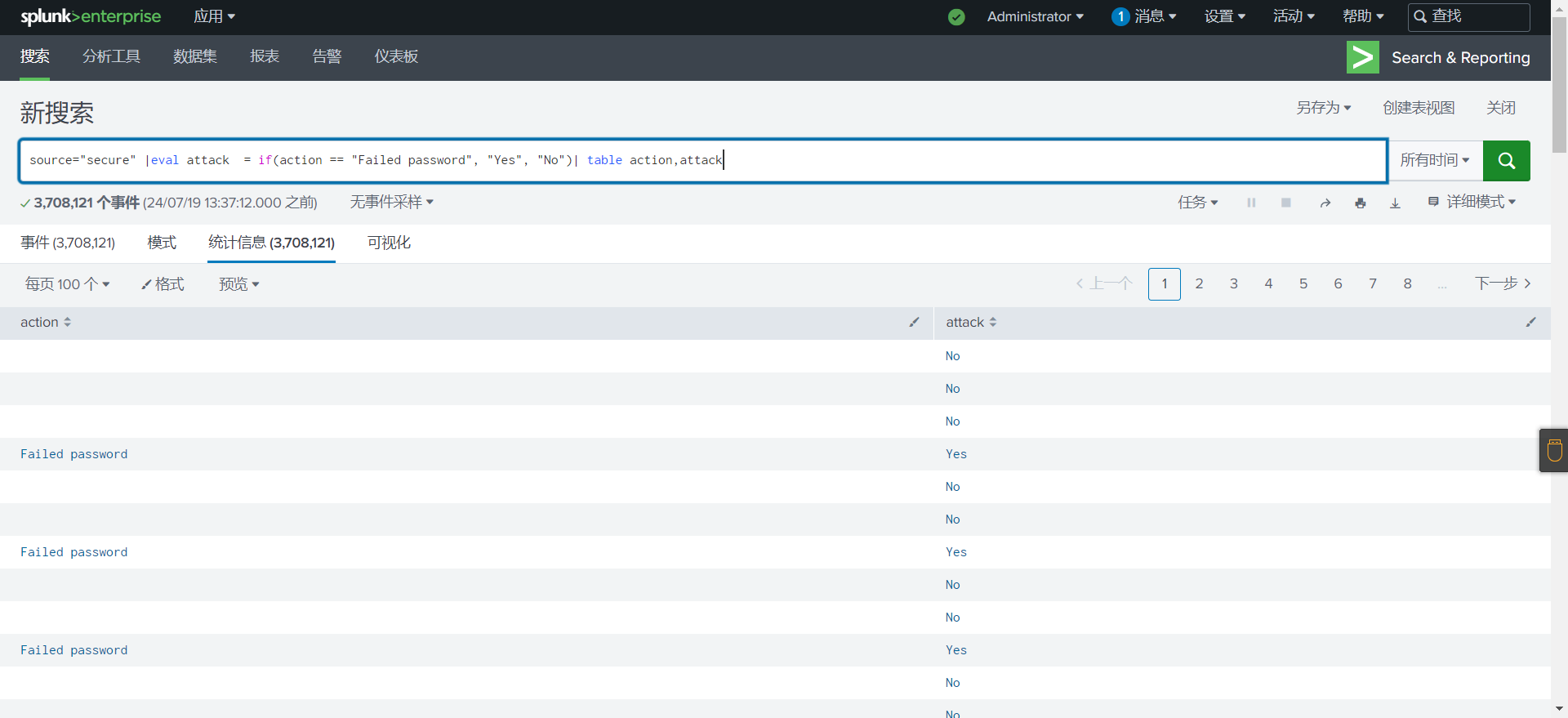
2# 在每个事件中创建一个名为 attack 的字段.如果 action值为Failed password,则使用 if 功能将 attack 字段中的值设置为Yes,否则为No
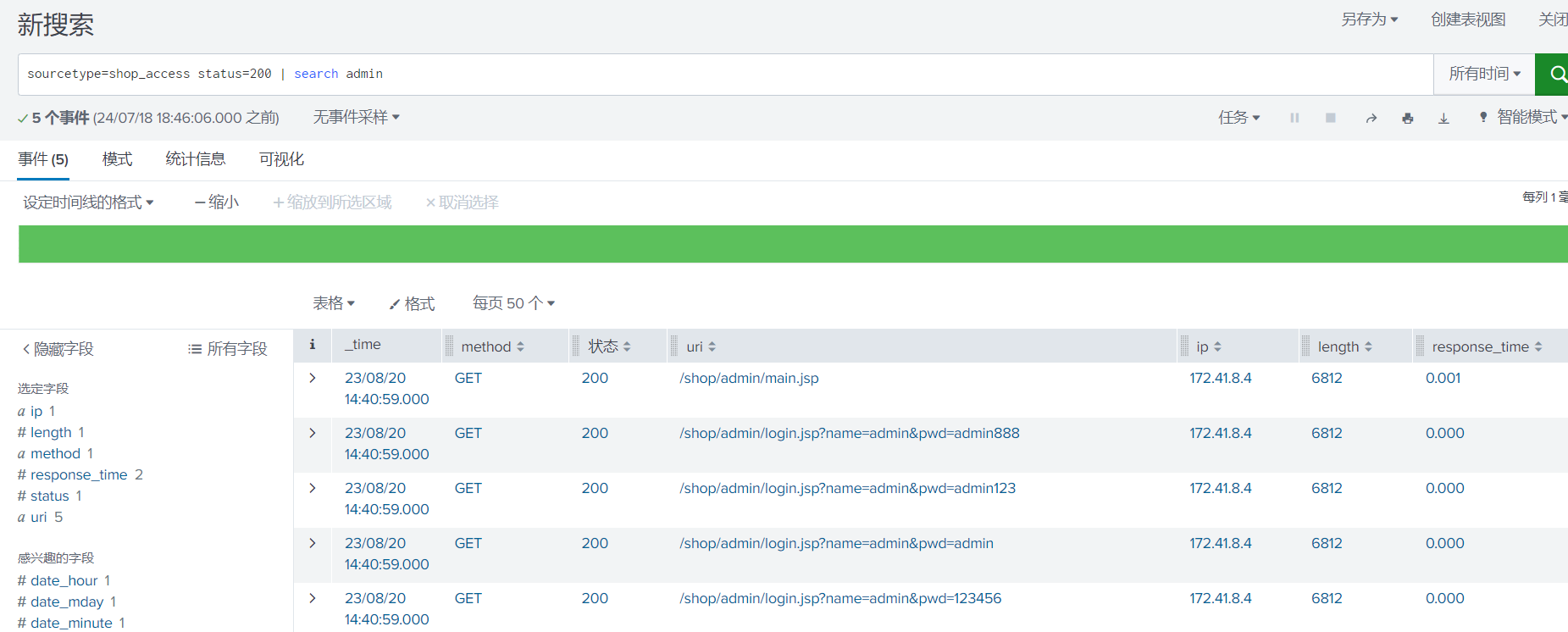
source="secure" |eval attack = if(action == "Failed password", "Yes", "No")| table action,attack将状态设置为一些简单的http错误代码
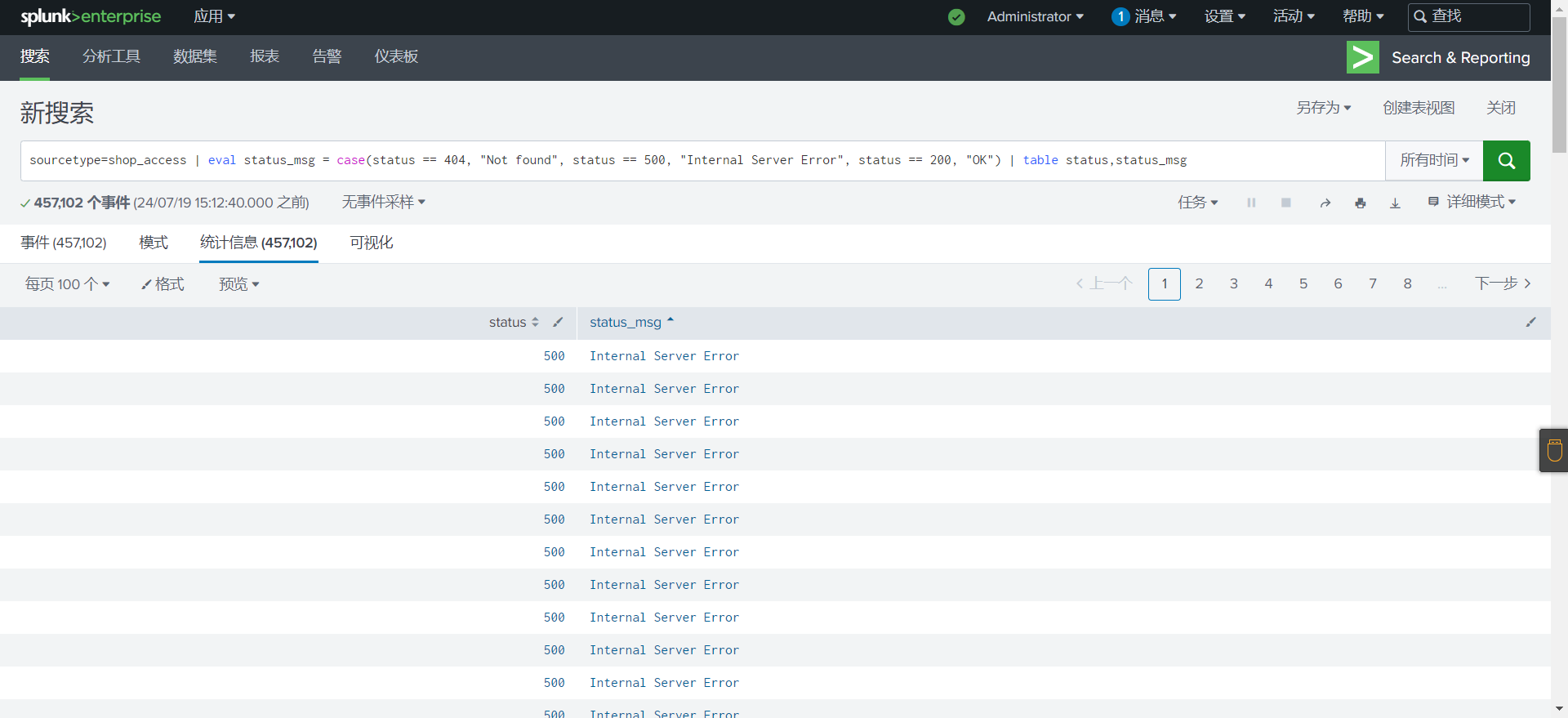
1
source="shop_access.log" | eval status_msg = case(status == 404, "Not found", status == 500, "Internal Server Error", status == 200, "OK") | table status,status_msg
rename
使用 rename 命令来重命名一个或多个字段.这个命令对于给字段赋予更有意义的名称非常有用,例如将 “pid” 改为 “Product ID”.如果你想重命名名称相似的字段,可以使用通配符.
1 | # 语法 |
示例
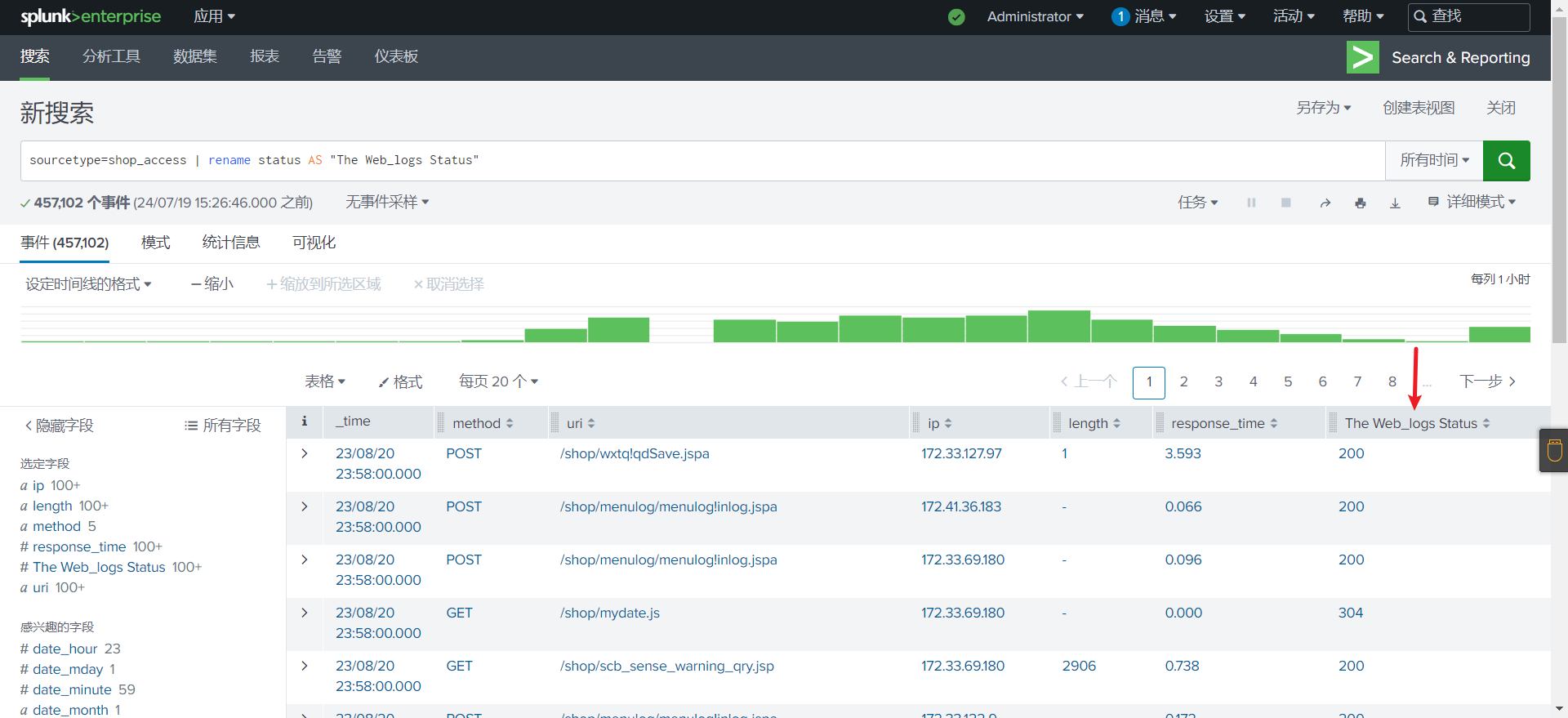
如果字段名称为短语时
1
2# 使用双引号将短语包裹起来
source="shop_access.log" | rename status AS "The Web_logs Status"多个名称相似的字段
1
2
3
4
5
6
7
8
9# 将以下字段的EU修改为EMEA
# EU_UK
# EU_DE
# EU_PL
| rename EU* AS EMEA*
# 修改后的内容
# EMEA_UK
# EMEA_DE
# EMEA_PL修改需转义的字段名
1
2# 如http\\:8000重命名为localhost:8000
| rename http\\\\:* AS localhost:*修改包含空格的字段名
1
| rename count AS "Count of Events"
数据聚合与统计命令
stats
计算结果集的聚合统计信息,如平均值、计数和总和.这类似于SQL聚合.如果在没有 BY 子句的情况下使用 stats 命令,则仅返回一行,这是整个传入结果集的聚合.如果使用 BY 子句,则为 BY 子句中指定的每个非重复值返回一行.
1 | # 语法 |
统计函数选项
1 | stats-function |
下表列出了按函数类型分类的支持函数.使用表中的链接可以查看每个函数的描述和示例.关于与命令一起使用函数的概述,请参见统计和图表函数.
| 函数类型 | 支持的函数和语法 |
|---|---|
| 聚合函数 | avg() count() distinct_count() estdc() estdc_error() exactperc<num>() max() median() min() mode() perc<num>() range() stdev() stdevp() sum() sumsq() upperperc<num>() var() varp() |
| 事件顺序函数 | first() last() |
| 多值统计和图表函数 | list() values() |
| 时间函数 | earliest() earliest_time() latest() latest_time() rate() |
示例
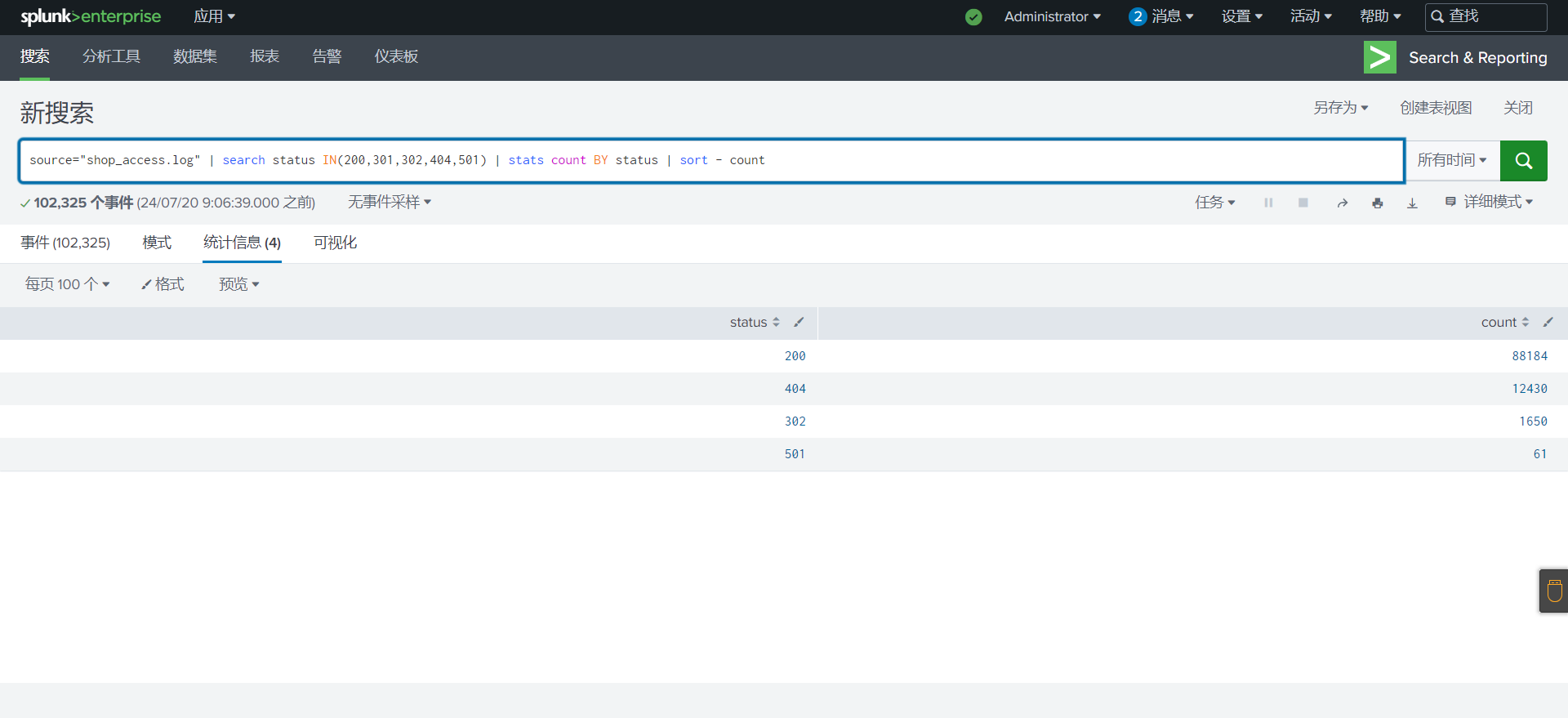
统计不同状态码的分布
1
source="shop_access.log" | search status IN(200,301,302,404,501) | stats count BY status | sort - count
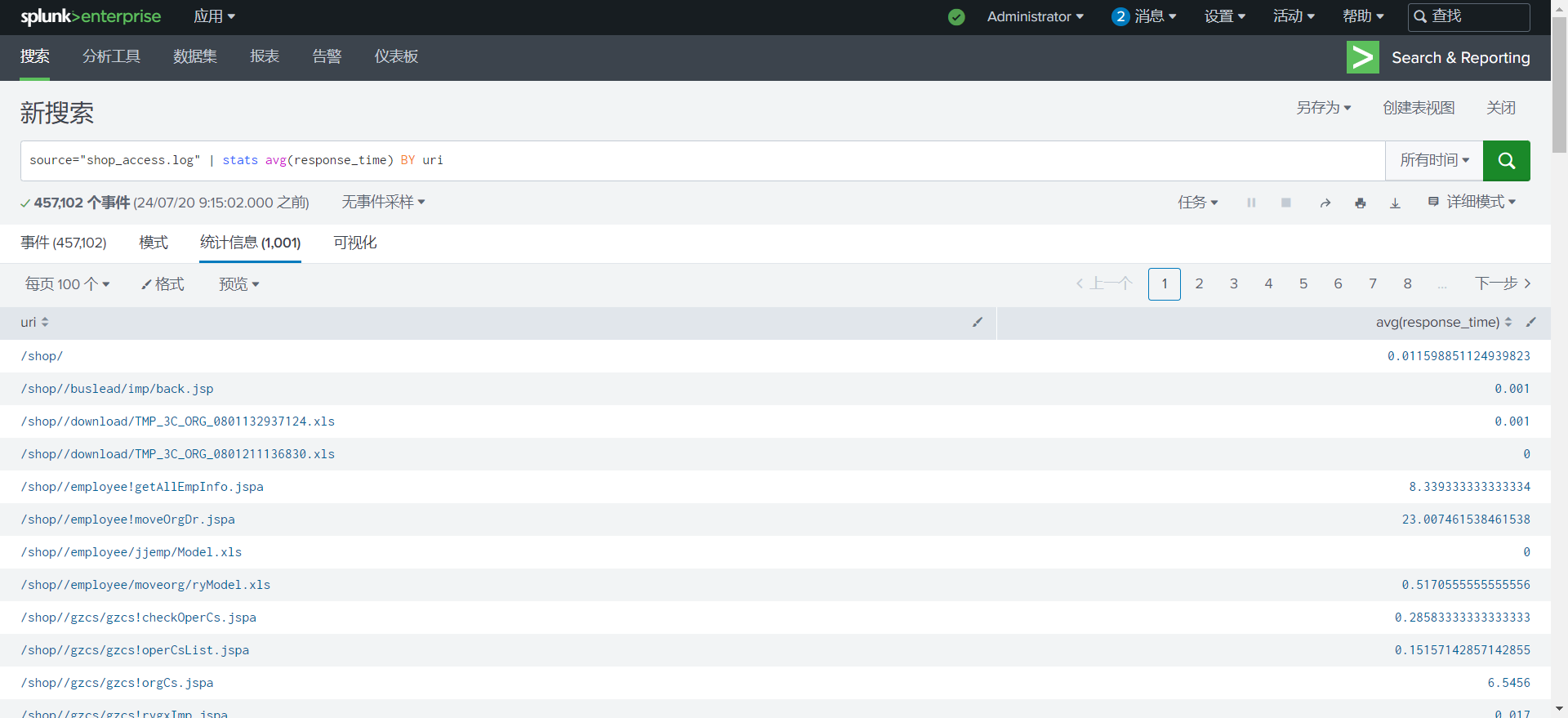
分析 HTTP 响应时间,识别是否有异常的响应时间.
1
source="shop_access.log" | stats avg(response_time) BY uri
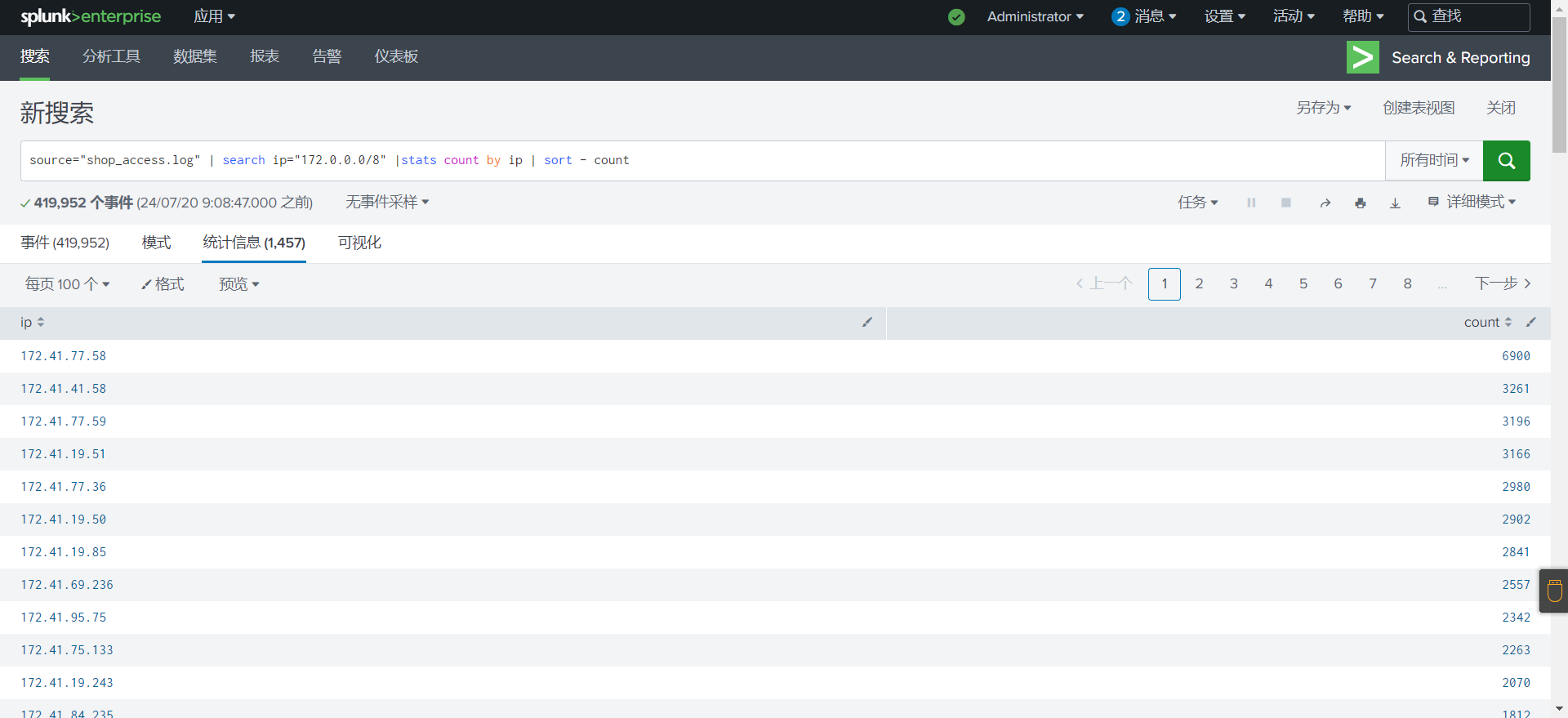
统计每个 IP 地址的访问次数,识别可能的攻击者 IP.
1
source="shop_access.log" |stats count by ip | sort - count
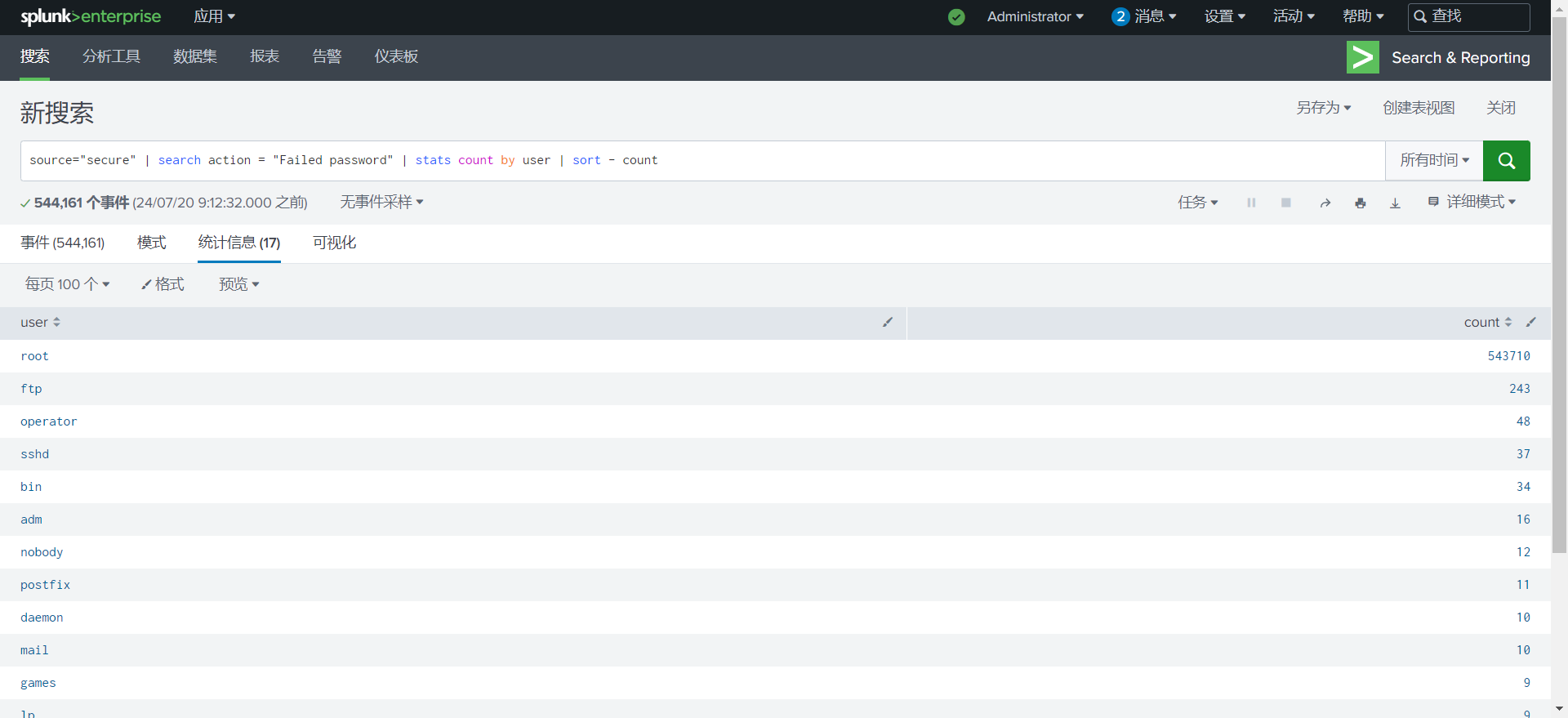
检测某个用户的登录尝试次数,识别是否有暴力破解行为.
1
source="secure" | search action = "Failed password" | stats count by user | sort - count
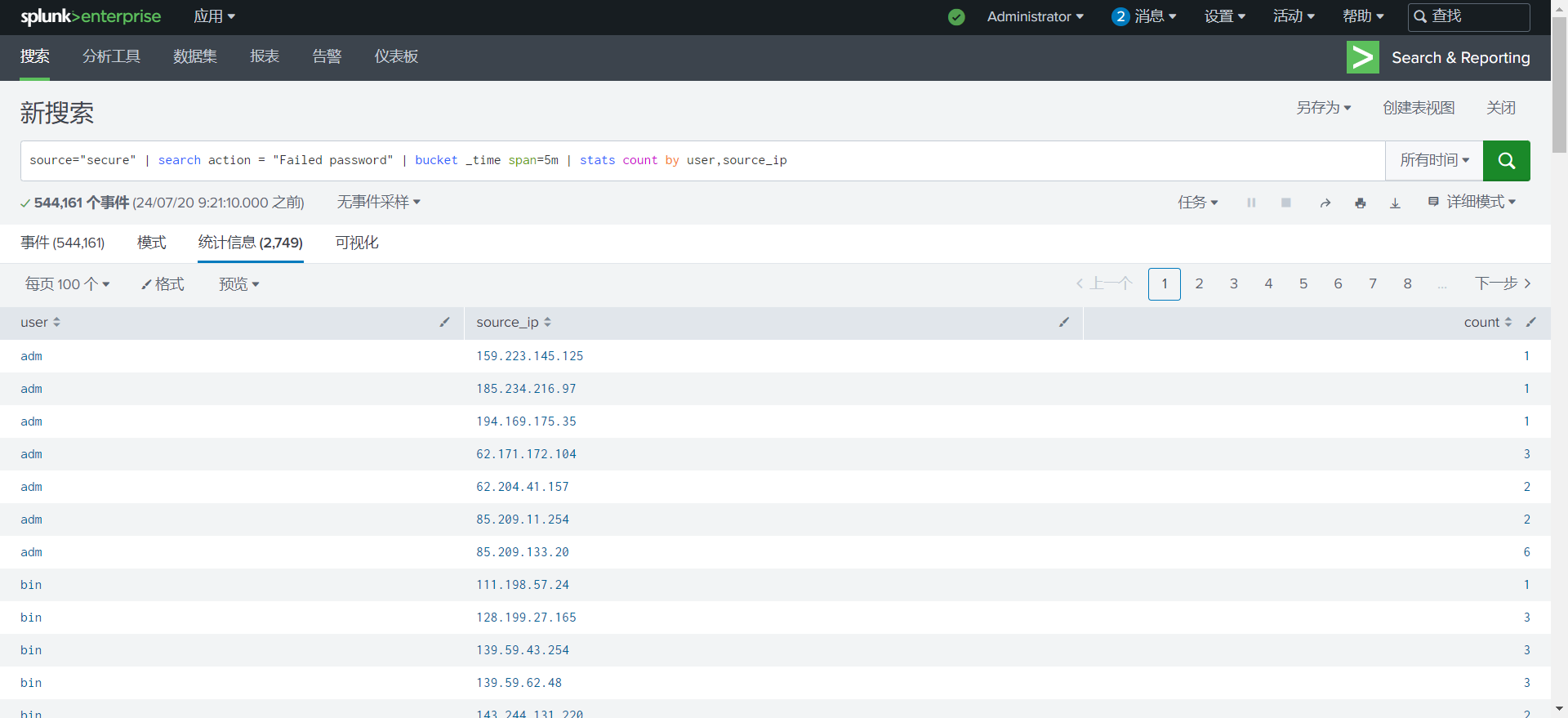
单一账号,5分钟内超过20次登录失败
1
source="secure" | search action = "Failed password" | bucket _time span=5m | stats count by user,source_ip
top
1 | # 查找字段列表中最常见的值.计算这些值在事件中出现的频率计数和百分比.如果包含 <by-clause>,则结果按你在 <by-clause> 中指定的字段进行分组. |
top选项
1 | # Top 选项 |
示例
返回字段的20个最常见值
1
2
3
4# 用户名
source="secure" | search action = "Failed password"| top limit=20 user
# 攻击IP
source="secure" | search action = "Failed password"| top limit=20 source_ip按
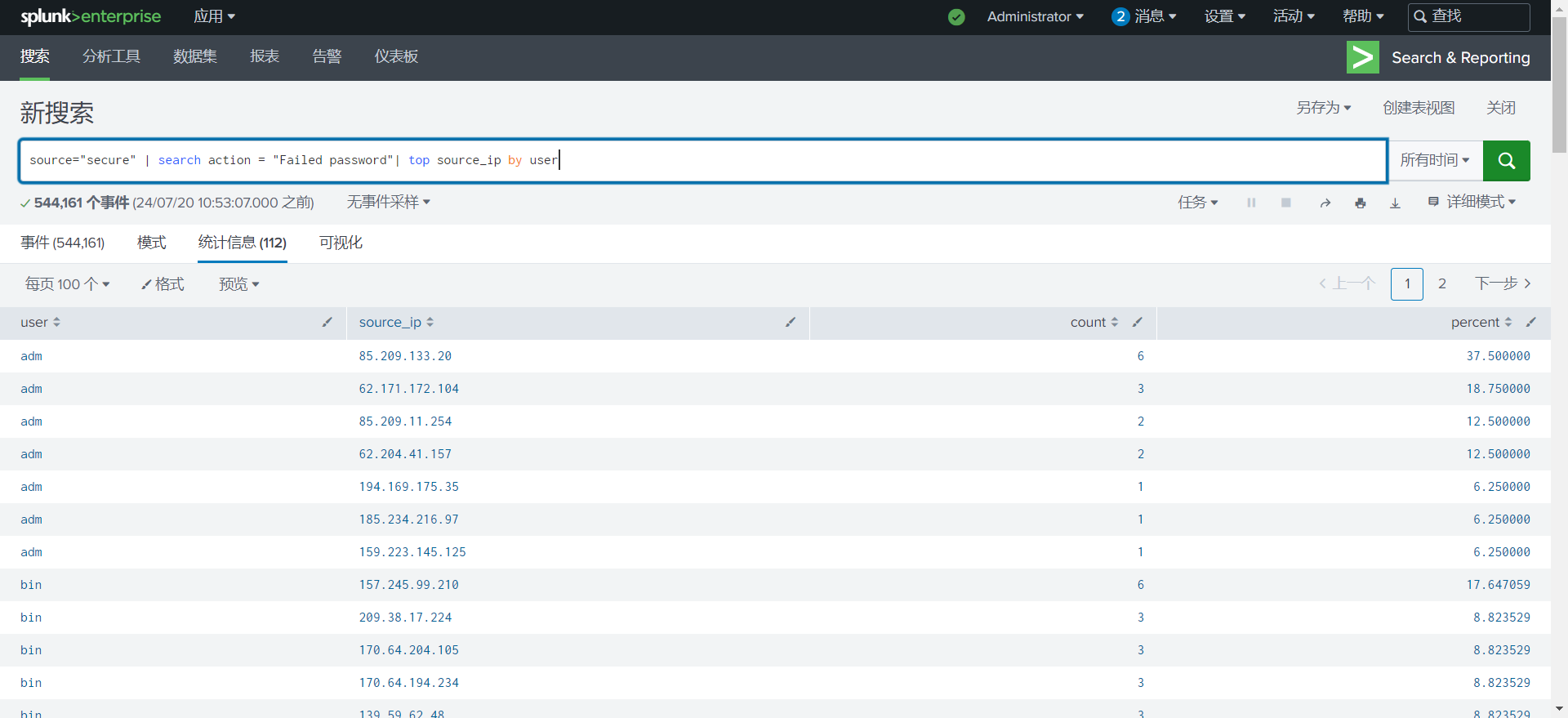
user字段分组,并计算source_ip的频率1
source="secure" | search action = "Failed password"| top source_ip by user
rare
显示字段中最不常用的值.
示例
返回字段中不常见的值
1
source="shop_access.log" | rare 20 uri
返回按uri字段中不常见的值
1
source="shop_access.log" | rare ip by uri
数据转换与操作命令
table
table 命令返回一个仅由参数中指定的字段组成的表.列的显示顺序与字段的指定顺序相同.列标题是字段名称.是字段值.每一行代表一个事件.
table 命令类似于 fields 命令,因为它允许您指定要在结果中保留的字段.当你想保留表格格式的数据时,使用 table 命令.
要优化搜索,请避免将 table 命令放在搜索的中间,而是将其放在搜索的末尾.
1 | # 语法 |
需要注意的是
- 要生成可视化图表,搜索结果必须包含数值、日期时间或聚合数据,如计数、求和或平均值.
- table 命令不允许你重命名字段,只能指定你希望在表格结果中显示的字段.如果你打算重命名字段,请在将结果传递给 table 命令之前进行.
- table 命令根据
limits.conf文件中的设置截断返回的结果数量.在search节中,如果truncate_report参数的值为 1,则返回的结果数量会被截断.结果数量由search节中的max_count参数控制.如果truncate_report设置为 0,则不应用max_count参数.
sort
sort 命令按指定字段对所有结果进行排序.如果顺序分别为降序或升序,则缺少给定字段的结果将被视为具有该字段的最小或最大可能值.
如果 sort 命令的第一个参数是一个数字,那么最多按顺序返回这么多结果.如果未指定数字,则使用默认限制10000.如果指定数字0,则返回所有结果.
1 | # 语法 |
示例
按
ip字段以升序对结果进行排序,然后按url字段以降序进行排序1
source="shop_access.log" | sort ip(ip),-str(uri)
按
length字段的降序对前100个结果排序,然后按uri值的升序排序1
source="shop_access.log" | sort -num(length),+str(uri)
按
_time字段升序对结果排序,然后按ip值降序对结果排序.1
source="shop_access.log" | sort _time, -host
返回最近的事件
1
source="shop_access.log" | sort 1 -_time
bin
通过调整·<field> 的值,将连续的数值放入离散的集合或区间(bins),使特定集合中的所有项目具有相同的值.
“箱数”: 指的是数据被分割成的不同组或类别的数量.在数据分析中,当我们说”箱数”时,我们通常是指将连续的数据值分成若干个区间或”箱子”,每个”箱子”包含一组特定的数据点.这样做可以帮助我们更直观地理解数据的分布情况.例如,如果你有一组学生的考试成绩,你可以将这些成绩分成几个”箱子”,比如60分以下、60-70分、70-80分等等,这样每个”箱子”就代表了一个分数段.
1 | # 语法 |
Bins-options
1 | # bins |
Span 选项
“对数基跨度”是一种用于将数据分箱的特殊方式,基于对数比例来确定每个箱子的范围.它并不是按照线性等间距来分箱,而是按照某个对数规则来分箱.
具体来说:
- 系数:这是对数跨度的第一个数字,表示每个箱子的宽度相对于前一个箱子的增长因子.
- 基数:这是对数跨度的第二个数字,表示对数的底数.
例如,如果你设置跨度为
2log10,这意味着你使用以10为底的对数,并且每个箱子的范围是前一个箱子的2倍.通俗地解释,对数基跨度就是根据对数的增长规律来划分数据,比如:
- 第一个箱子可能是1-10,
- 第二个箱子是10-100,
- 第三个箱子是100-1000,
依此类推.每个箱子的范围按对数增长,而不是等间距增长.这样做有助于处理数据范围非常广泛的情况,使得每个箱子能更好地代表不同数量级的数据.
1 | # log-span |
时间尺度
1 | <timescale> |
| 时间尺度 | 语法 | 描述 |
|---|---|---|
| <sec> | s | sec | secs | second | seconds | 秒为单位的时间尺度. |
| <min> | m | min | mins | minute | minutes | 分钟为单位的时间尺度. |
| <hr> | h | hr | hrs | hour | hours | 小时为单位的时间尺度. |
| <day> | d | day | days | 天为单位的时间尺度. |
| <month> | mon | month | months | 月为单位的时间尺度. |
| <subseconds> | us | ms | cs | ds | 微秒 (us)、毫秒 (ms)、厘秒 (cs) 或十分之一秒 (ds) 为单位的时间尺度. |
示例
1天内超过3个城市登录即可视为异地登录异常.
1
source="secure" action="Filed password" | bin _time span=1d |iplocation ip | stats values(ip) as ip values(City) as City dc(City) as src_count by user|search src_count>3
1天内同一个ip登录超过10个账号
1
source="secure" action="Accepted" | bin _time span=1d | stats count(user) by ip| rename count(user) as User_count | search User_count>10
凌晨0点到早上8点内,登录成功的账号.
1
source="secure" action="Accepted" date_hour<8 | table _time,ip,user
删除索引数据
当您添加数据时,索引器将处理数据并将其存储在索引中.默认情况下,提供给索引器的数据存储在主索引中,可以为不同的数据输入创建和指定其他索引.
索引是目录和文件的集合.它们位于 $SPLUNK_HOME/var/lib/splunk 下.索引目录也称为存储桶,按时间组织.
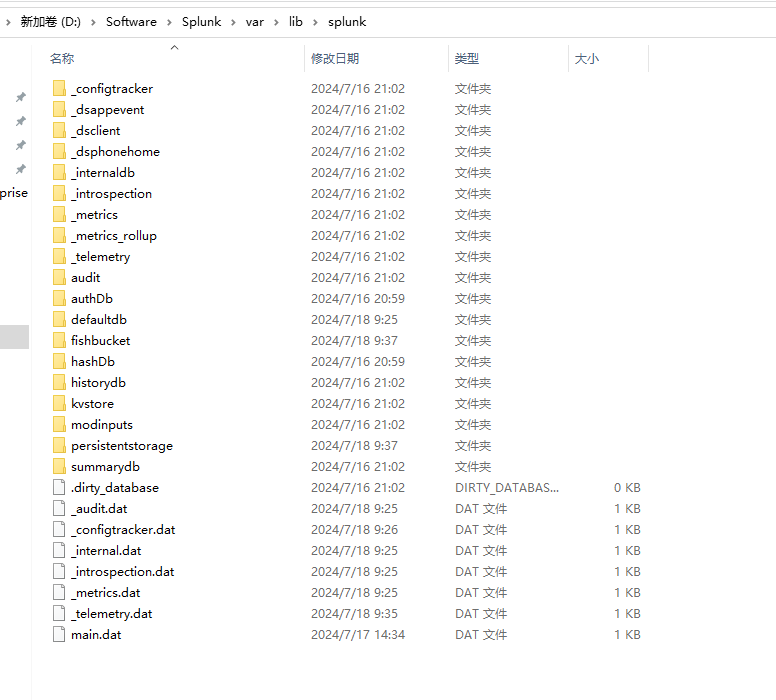
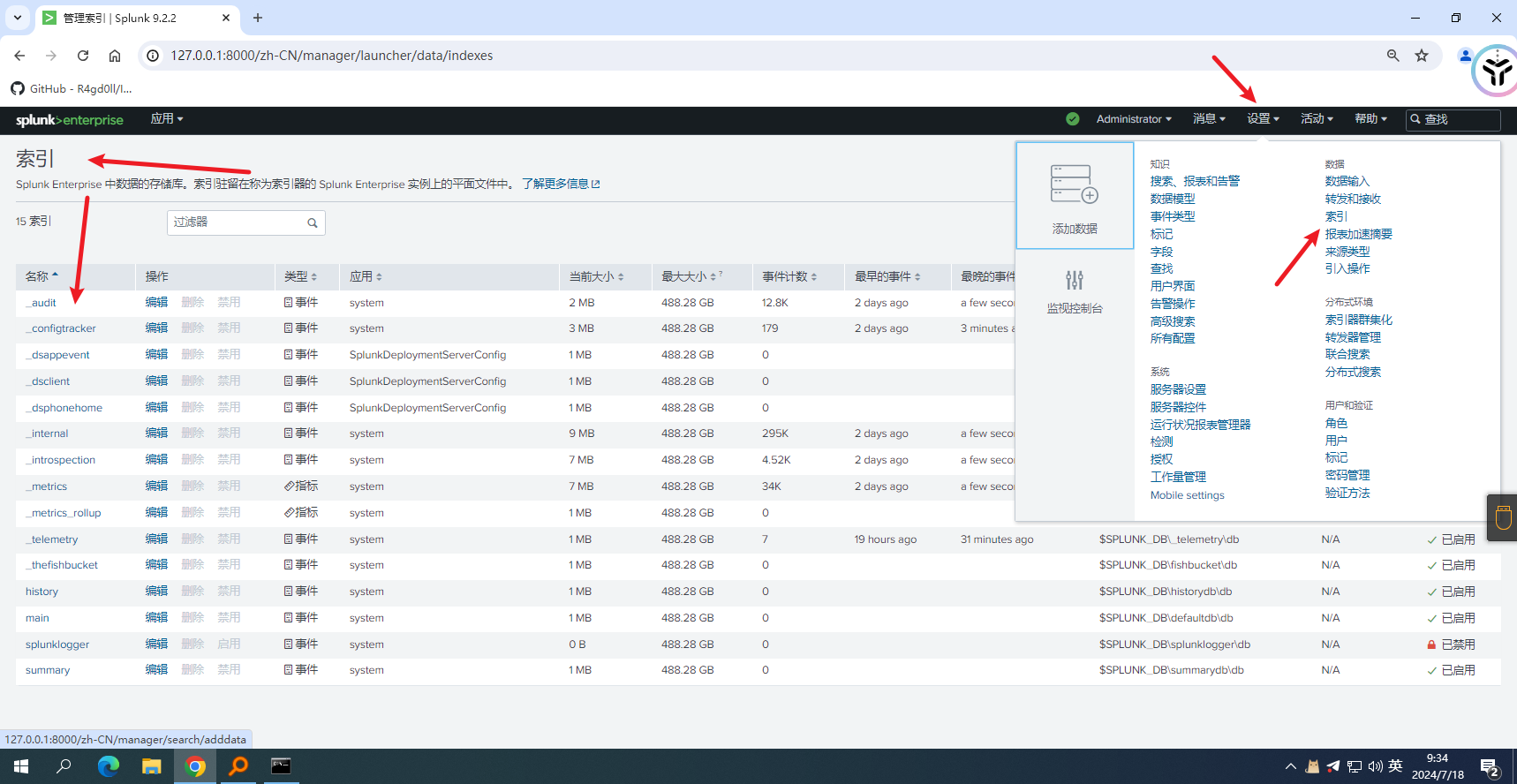
除了主索引之外,Splunk Enterprise还预配置了许多内部索引.内部索引开始以下划线_开头;例如_audit和_internal.
要查看内部索引的完整列表,请转到Splunk Web,选择导航–>设置—>索引.
删除索引和索引数据
从索引器中删除索引数据甚至整个索引.这些是主要的选择:
- 从后续搜索中删除事件.
- 从一个或多个索引中删除所有数据.
- 删除或禁用整个索引.
删除数据是不可逆的.如果希望在使用本教程中介绍的任何技术删除数据后恢复数据,则必须对适用的数据源重新编制索引.
从后续搜索中删除事件
Splunk 的搜索语言提供了 delete 命令,用来从后续的搜索结果中删除事件数据.这个命令只能用于事件索引,不能用于度量索引.
需要注意的是,你不能在实时搜索中使用 delete 命令.如果你在实时搜索中尝试使用这个命令,Splunk Enterprise 会显示错误.
度量索引(Metrics Index)是Splunk中的一种特殊类型的索引,专门用于存储和处理时间序列数据,例如性能指标、统计数据或其他度量数据.与传统的事件索引不同,度量索引针对高效存储和快速检索设计,特别适合处理大量、频繁更新的数据.
delete 命令仅从后续搜索中删除事件.数据本身仍保留在索引中.
delete 命令只能由具有delete_by_keyword功能的用户运行.默认情况下,Splunk Enterprise附带了一个特殊的角色can_delete,它具有此功能(没有其他功能).默认情况下,管理员角色没有此功能.建议您创建一个特殊用户,以便在删除索引数据时登录到该用户.
首先运行一个搜索,返回您要删除的事件.请确保此搜索仅返回要删除的事件,而不返回其他事件.一旦确定了这一点,就可以将搜索结果传递给 delete 命令.
例如,如果要从名为 shop_access.log 的源中删除已编入索引的事件,使其不再出现在搜索中,请执行以下操作:
- 禁用或删除该源,使其不再被索引.
- 在索引中搜索来自该源的事件:
1
source="shop_access.log"
- 查看结果以确认这是您要删除的数据.
- 确认这是您要删除的数据后,将搜索路径设置为
delete将搜索连接到1
source="shop_access.log" | delete
delete命令会标记该搜索返回的所有事件,以便后续搜索不会返回这些事件.任何用户(即使具有管理员权限)在搜索时都无法看到此数据.注意!!!连接到
delete不会回收磁盘空间.数据实际上并没有从索引中删除;它只是对搜索不可见.delete命令不会更新事件的元数据,因此任何元数据搜索仍将包括事件,尽管它们不可搜索.主“所有索引数据”仪表板仍将显示已删除源、主机或源类型的事件计数.
从一个或所有索引中删除所有数据
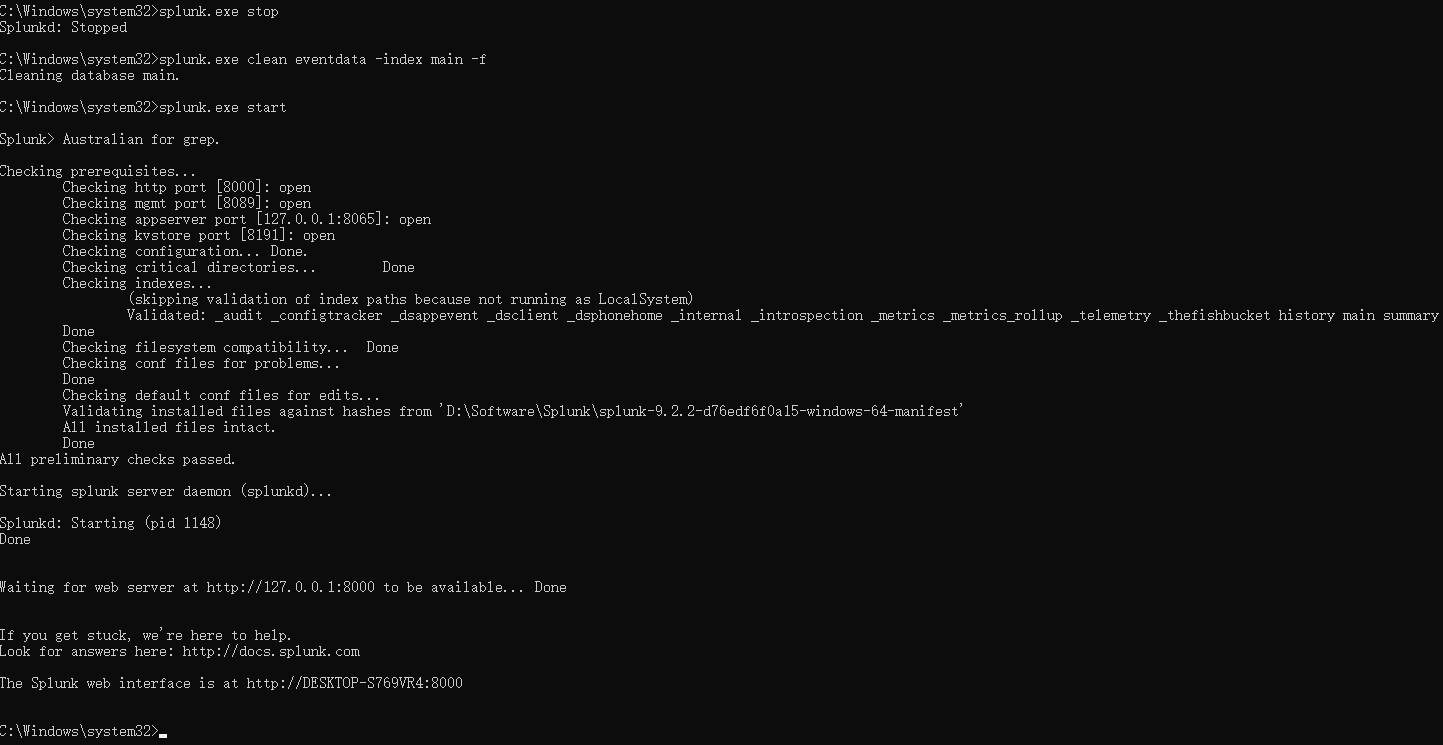
要从磁盘中永久删除索引数据,请使用CLI clean 命令.
此命令完全删除一个或所有索引中的数据,具体取决于您是否提供了 <index_name> 参数.
通常,在重新索引所有数据之前运行 clean .
注意: clean 命令不适用于聚集索引.
以下是使用 clean 命令的主要方法:
要访问
clean的帮助页面,请键入以下内容:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63D:\Software\Splunk\bin>splunk.exe help clean
警告:服务器证书主机名验证已禁用.请参阅 server.conf/[sslConfig]/cliVerifyServerName 了解详情.
clean 命令用于删除 Splunk 安装中的事件数据、全局数据和用户账户数据.
永久删除索引中的事件数据,请输入 "./splunk clean eventdata".设置 index 参数以删除特定索引中的事件数据.如果不设置索引,Splunk 将删除所有索引中的所有事件数据.
通过输入 "./splunk clean globaldata" 删除 Splunk 中的全局数据(你索引的事件的标签和源类型别名).
通过输入 "./splunk clean userdata" 删除 Splunk 中的用户数据(你创建的用户账户).
** 注意: **
删除数据是不可逆的.在选择要从 Splunk 安装中删除的数据时请谨慎.如果需要恢复数据,必须重新索引适用的数据源.
** 提示: **
添加 -f 参数以强制 clean 跳过其确认提示.
语法:
clean eventdata [-f] [-index <名称>] [--remote=<布尔值>]
clean (globaldata|userdata|locks|all|deployment-artifacts) [-f]
clean all [--remote=<布尔值>]
clean inputdata [<方案>]
clean kvstore [-f] (-local|-all|-app <应用名称>|-app <应用名称> -collection <集合名称>|-cluster)
clean raft [-f]
对象:
eventdata 导出的作为原始日志文件索引的事件
globaldata 主机标签,源类型别名
userdata 用户账户
inputdata 模块化输入检查点数据
locks 内部锁文件(仅在 Splunk 支持建议时)
kvstore 应用程序键/值存储数据库
raft 搜索头集群 raft 配置
all 上述所有内容;*不包括* deployment-artifacts
deployment-artifacts 由实例创建的文件,该实例曾作为部署服务器或部署客户端
(仅在 Splunk 支持建议时)
必需参数:
eventdata 如果没有指定索引,默认是清理所有索引
inputdata 如果没有指定模块化输入方案,默认是清理所有注册的模块化输入的数据
kvstore 没有默认模式,必须给定有效模式
可选参数:
eventdata index 应清理事件数据的索引名称
f 强制 clean 跳过其确认提示
(清理无法撤销.请谨慎使用!)
--remote= <true/ false> 覆盖默认配置并清理/跳过远程索引
globaldata f 强制 clean 跳过其确认提示
(清理无法撤销.请谨慎使用!)
userdata f 强制 clean 跳过其确认提示
(清理无法撤销.请谨慎使用!)
kvstore local 删除本地键值存储数据库
all 从所有应用集合中删除数据
app 从特定应用集合中删除数据
collection 从特定集合中删除数据
(只能与 app 参数一起使用)
cluster 删除当前 kvstore 集群配置
(当你想将当前实例移出 SHC/SHP 并保留数据时使用)
f 强制 clean 跳过其确认提示
(清理无法撤销.请谨慎使用!)
raft f 强制 clean 跳过其确认提示
(清理无法撤销.请谨慎使用!)
all --remote= <true/ false> 覆盖默认配置并清理/跳过远程索引
示例:
./splunk clean eventdata
./splunk clean globaldata
./splunk clean eventdata -index main -f
./splunk clean eventdata --remote=true
./splunk clean inputdata s3
输入 "help [对象|主题]" 查看特定对象或主题的帮助.
完整的文档可在以下网址在线获取:http://docs.splunk.com/Documentation关闭
splunksplunk.exe clean eventdata -index main -f启动
splunk
完全删除索引
要从非集群索引器中完全删除索引(而不仅仅是其中包含的数据),使用Splunk Web或CLI.也可以直接编辑 indexes.conf
在删除索引之前,请查看索引器上的所有 inputs.conf 文件以及向索引器发送数据的任何转发器,并确保没有任何节将数据定向到您计划删除的索引.例如,如果你想删除一个名为nogood的索引,请确保以下属性/值对不会出现在你的任何输入节中: index=nogood .一旦索引被删除,索引器将丢弃仍发送到该索引的任何数据.
要在Splunk Web中删除索引,请导航到设置>索引,然后单击要删除的索引右侧的删除.此操作将删除索引的数据目录,并从 indexes.conf 中删除索引的节.
1 | # 通过CLI删除索引 |
此命令删除索引的数据目录,并从 indexes.conf 中删除索引的节.
在索引器运行时运行 splunk remove index .命令完成后,无需重新启动索引器.也可以通过直接编辑 indexes.conf 并删除索引的节来删除索引.重新启动索引器,然后删除索引的目录
要从索引器集群中删除索引,必须编辑 indexes.conf 并删除索引的节.您不能使用Splunk Web或CLI.与索引器群集上的所有此类更改一样,首先在管理器节点上编辑文件,然后将更改应用于对等节点.请参阅在索引器集群中配置对等索引应用了 indexes.conf 更改并且对等节点重新启动后,请从每个对等节点中删除索引的目录.
禁用索引而不将其删除
索引一旦被禁用,索引器就不再接受针对它的数据.但是,禁用索引不会删除索引数据,并且该操作是可逆的.
在Splunk Web中禁用索引.要执行此操作,请导航到设置>索引,然后单击要禁用的索引右侧的禁用.要重新启用索引,请单击索引右侧的启用.
也可以使用CLI命令:
1 | # 禁用索引 |
要禁用索引器集群的索引,必须在索引节中编辑 indexes.conf 并设置 disabled=true .您不能使用Splunk Web或CLI.与索引器群集上的所有此类更改一样,首先在管理器节点上编辑文件,然后将更改应用于对等节点.



