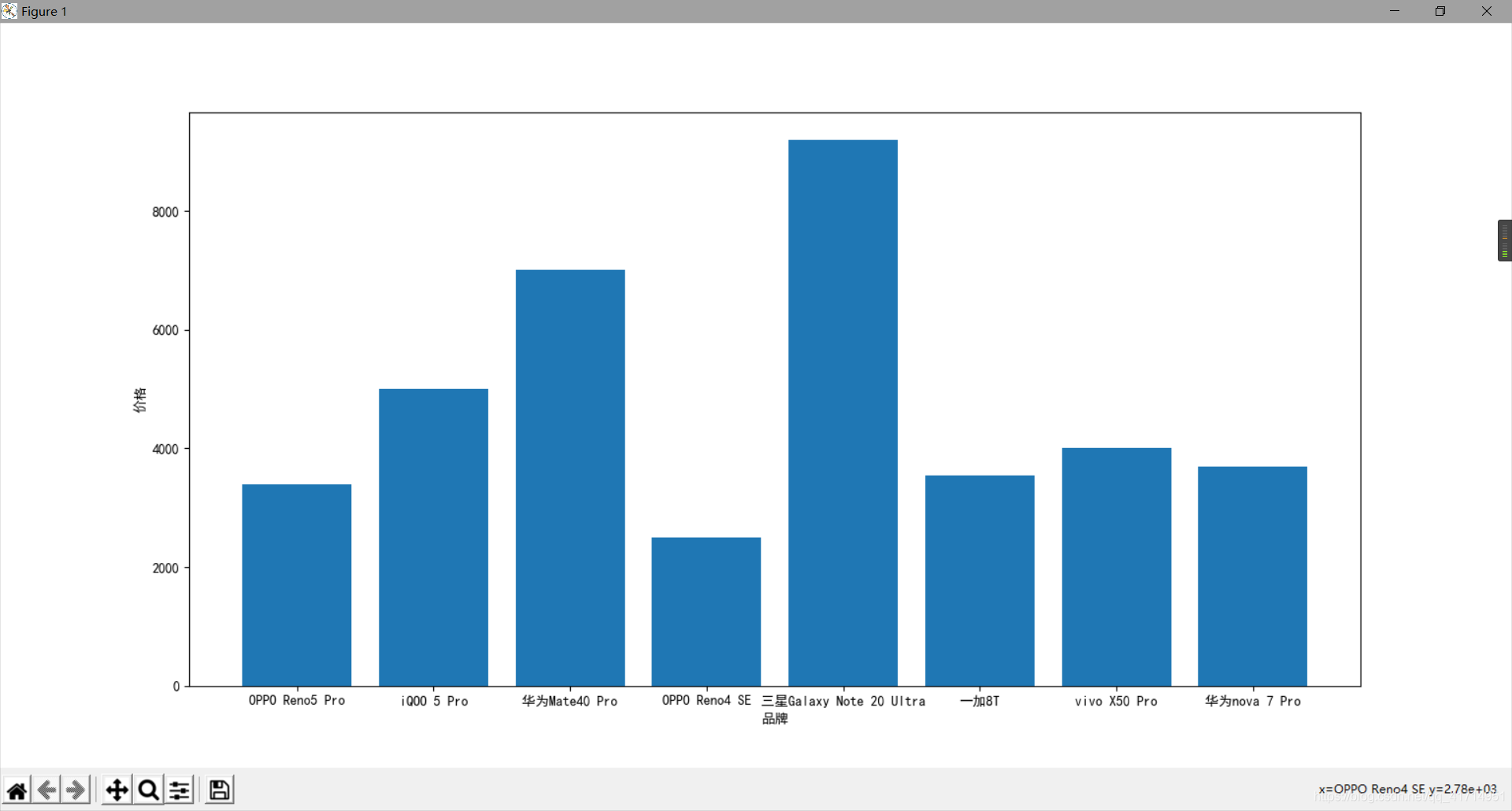
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| def get_articles_list():
title_list = []
price_list = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
url = 'http://top.zol.com.cn/compositor/57/cell_phone.html'
page = requests.get(url, headers=headers).text
page_text = etree.HTML(page)
li_list = page_text.xpath(
'//div[@class="rank-list"]/div')
for li in li_list:
title = li.xpath('./div[3]/div[1]/a/text()')
price = li.xpath('./div[4]/div/text()')
for t, p in zip(title, price):
t = re.sub(r"[\uFF08-\uFF09].*[\uFF08-\uFF09]", "", t)
if p != '概念产品':
title_list.append(t)
p = p[1:len(p)]
price_list.append(int(p))
else:
p = 99999999
title_list.append(t)
price_list.append(p)
return title_list, price_list
|