总字符数: 25.54K
代码: 17.89K, 文本: 3.33K
预计阅读时间: 1.54 小时
Matplotlib
matplotlib基本要点
基本使用
1 | from matplotlib import pyplot as plt#导入pyplot |
图片大小
1 | plt.figure(figsize=(20,8),dpi=80) |
x/y轴刻度
1 | # 标签竖着显示 |
中文显示
1 | # 设置matplotlib正常显示中文和负号 |
描述信息
1 | plt.xlabel('x轴描述信息') |
图形网格
1 | plt.grid(alpha=0.4)#绘制网格,alpha:透明度 |
图例
1 | #散点图 |
自定义绘制图形风格
1 | plt.plot(x,y,color='r',linestyle='--',linewidth=5,alpha=0.5)#color线条颜色,linestyle线条风格,linewidth线条粗细,alpha透明度 |
| 颜色字符 | 描述 | 风格字符 | 描述 |
|---|---|---|---|
r |
红色 | - |
实线 |
g |
绿色 | -- |
虚线 |
b |
蓝色 | -. |
点划线 |
c |
青色 | : |
点线 |
m |
洋红色 | 或 '' |
无线条 |
y |
黄色 | ||
k |
黑色 | ||
#00ff00 |
16进制颜色值 | ||
0.8 |
灰度值字符串 |
折线图
动手
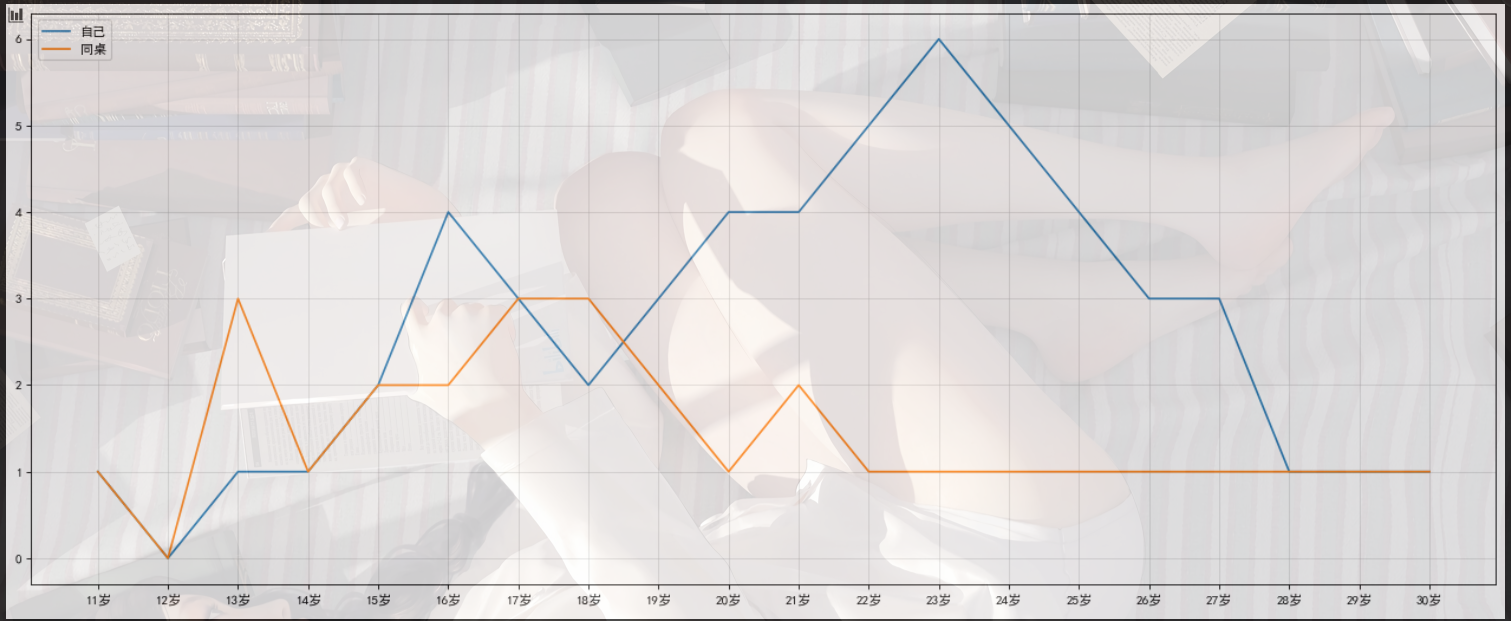
假设大家在30岁的时候,根据自己的实际情况,统计出来了你和你同桌各自从11岁到30岁每年交的女(男)朋友的数量如列表a和b,请在一个图中绘制出该数据的折线图,以便比较自己和同桌20年间的差异,同时分析每年交女(男)朋友的数量走势
1 | a = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1] |
代码:
1 | y_1 = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1] |
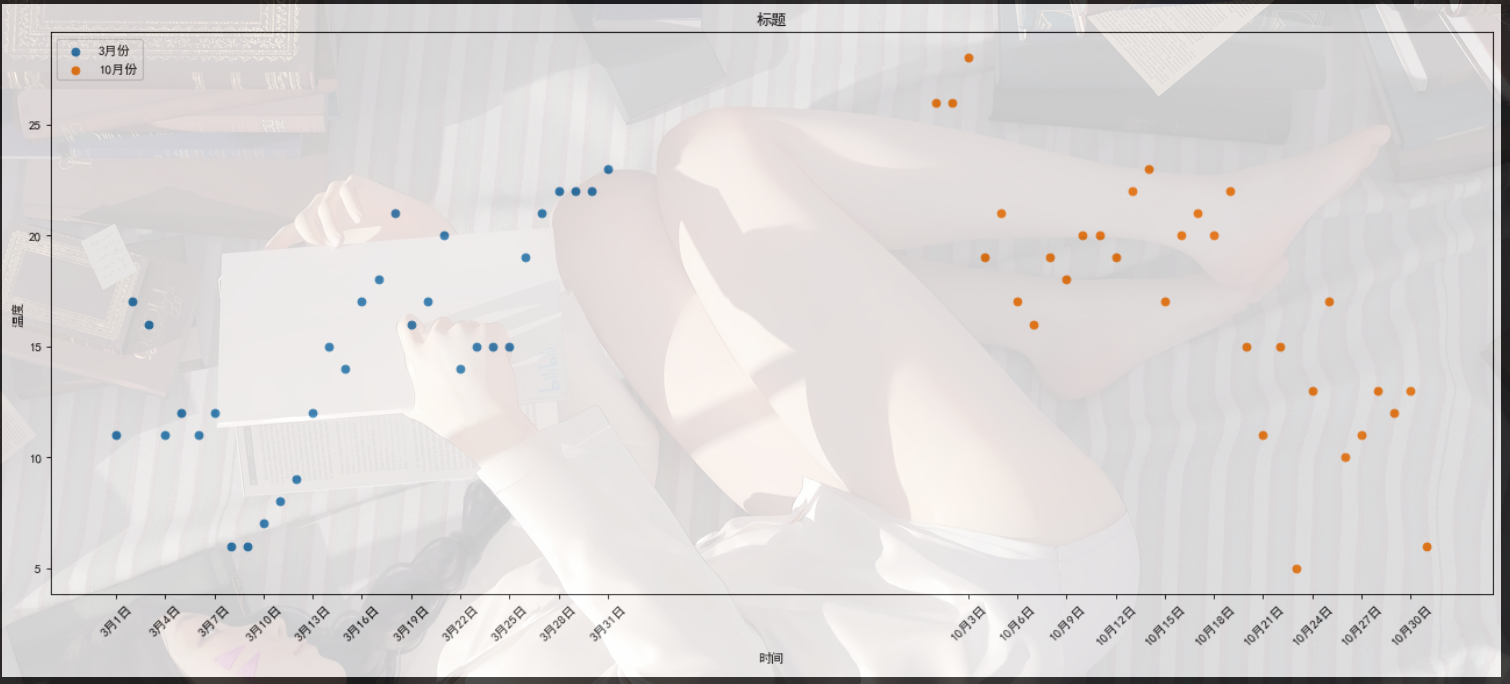
散点图
1 | #散点图 |
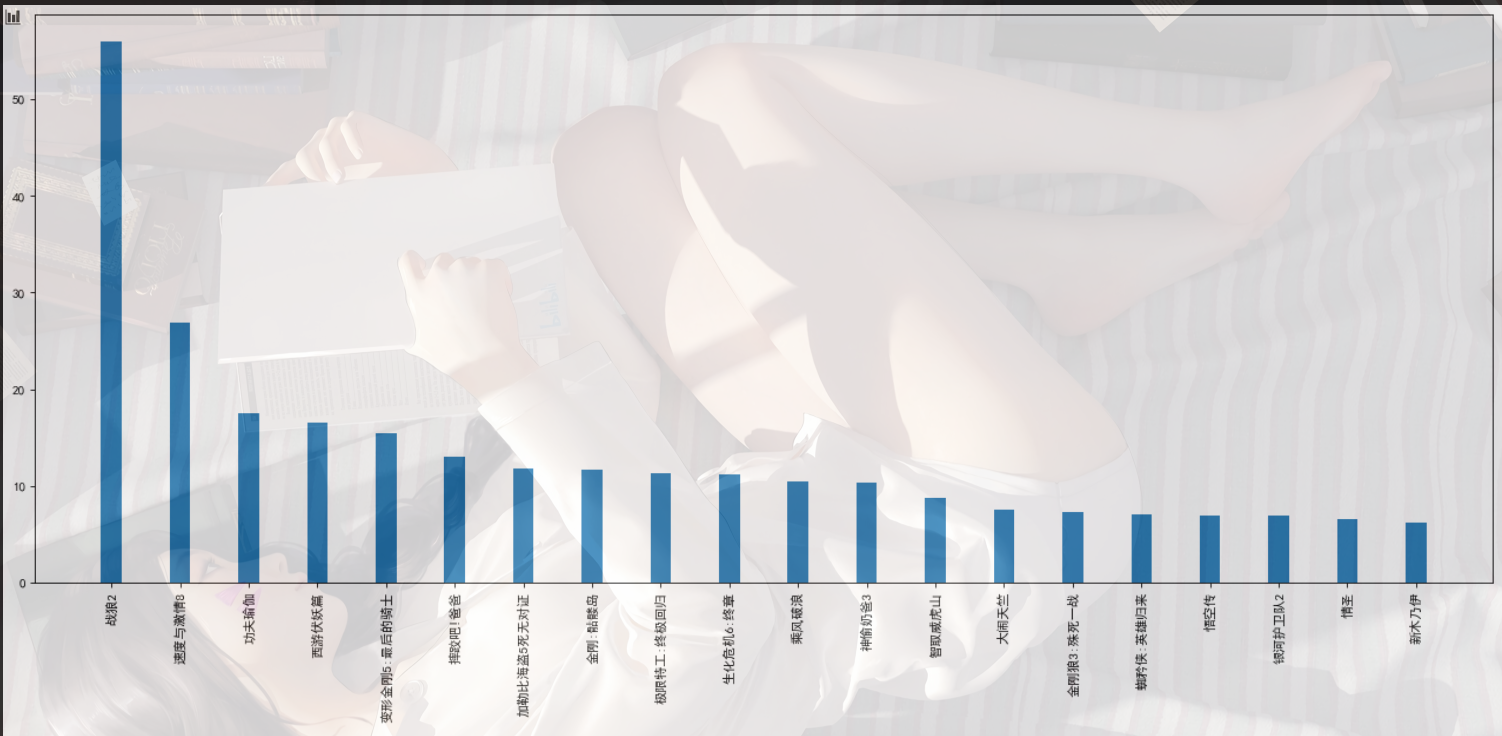
条形图
1 | #绘制条形图 |
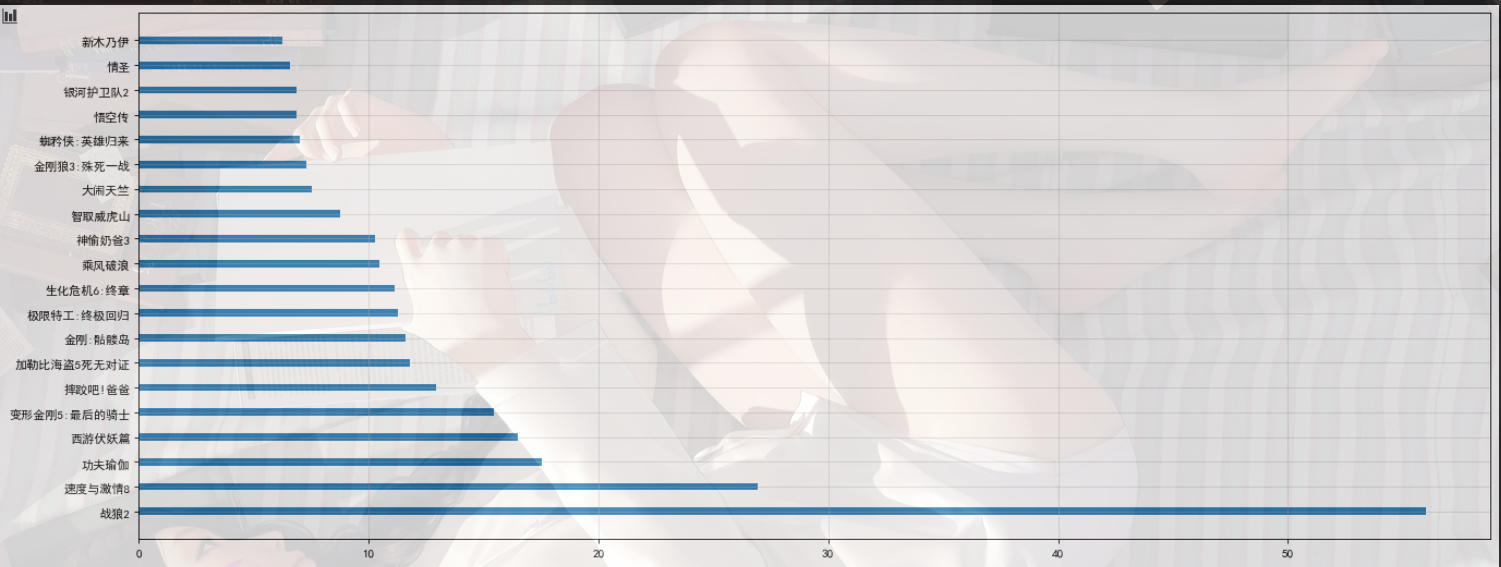
1 | #绘制横着的条形图 |
多条形图
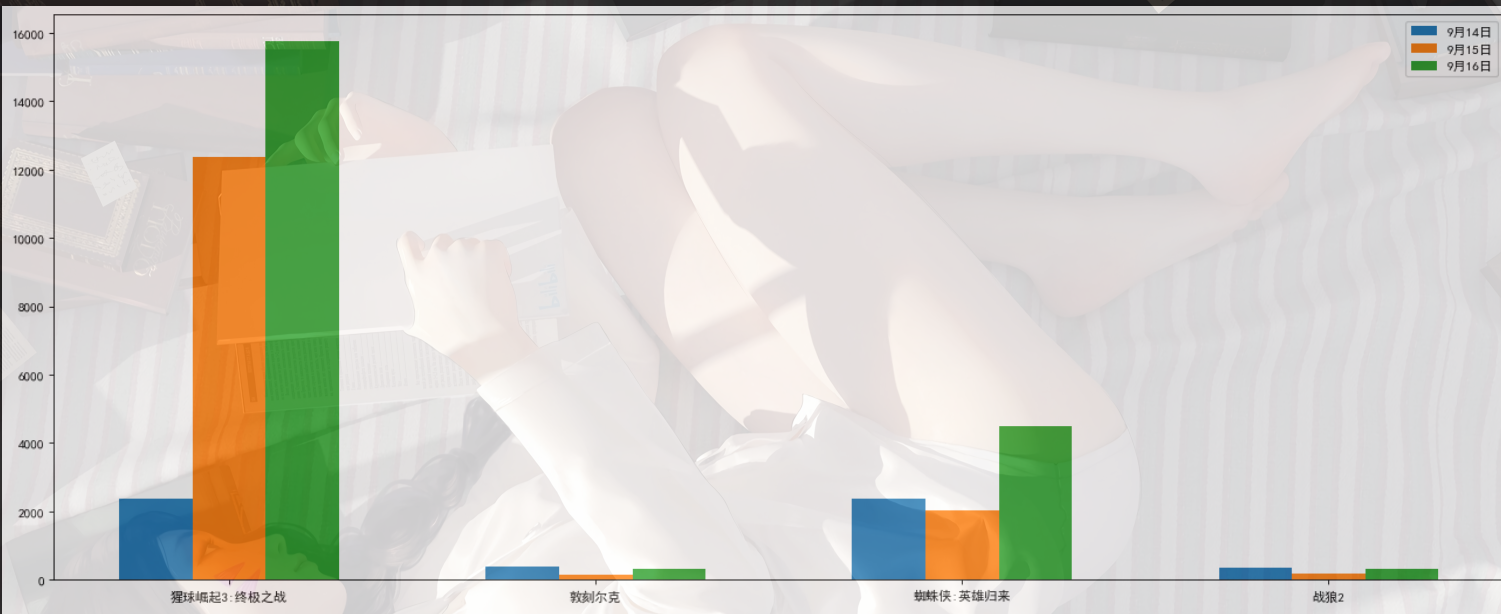
1 | # 假设你知道了列表a中电影分别在2017-09-14(b_14),2017-09-15(b_15),2017-09-16(b_16)三天的票房,为了展示列表中电影本身的票房以及同其他电影的数据对比情况,应该如何更加直观的呈现该数据? |
直方图
把数据分为多少组进行统计???
组数要适当,太少会有较大的统计误差,大多规律不明显
组数:将数据分组,当数据在100个以内时,
按数据多少常分5-12组.
组距:指每个小组的两个端点的距离
1 | bin_width = 3#设置组距为3 |
1 | #直方图 |
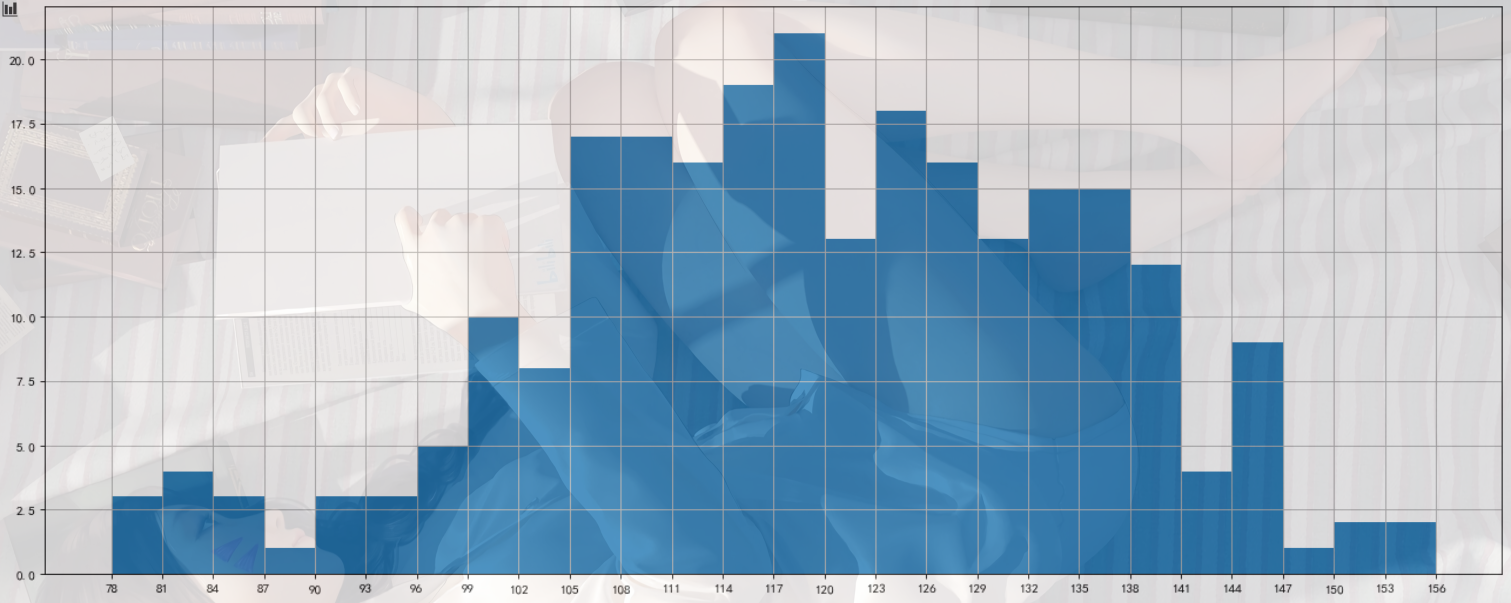
用条形图绘制直方图
1 | #在美国2004年人口普查发现有124 million的人在离家相对较远的地方工作.根据他们从家到上班地点所需要的时间,通过抽样统计(最后一列)出了下表的数据,这些数据能够绘制成直方图么? |
Numpy
什么是numpy
一个在Python中做科学计算的基础库,重在数值计算,也是大部分PYTHON科学计算库的基础库,多用于在大型、多维数组上执行数值运算
numpy基础
numpy创建数组(矩阵)
1 | #numpy |
numpy中的数据类型
| 类型 | 类型代码 | 说明 |
|---|---|---|
| int8、uint8 | i1、u1 | 有符号和无符号的8位(1个字节)整型 |
| int16、uint16 | i2、u2 | 有符号和无符号的16位(2个字节)整型 |
| int32、uint32 | i4、u4 | 有符号和无符号的32位(4个字节)整型 |
| int64、uint64 | i8、u8 | 有符号和无符号的64位(8个字节)整型 |
| float16 | f2 | 半精度浮点数 |
| float32 | f4或f | 标准的单精度浮点数.与C的float兼容 |
| float64 | f8或d | 标准的双精度浮点数.与C的double和Python的float对象兼容 |
| float128 | f16或g | 扩展精度浮点数 |
| complex64、complex128 | c8、c16 | 分别用两个32位、64位或128位浮点数表示的 |
| complex256 | c32 | 复数 |
| bool | ? | 存储True和False值的布尔类型 |
1 | #指定创建的数组的数据类型: |
数组的形状
1 | import numpy as np |
数组的计算
数组和数的计算
1 | t5 |
数组和数组的计算
1 | t5 |
广播原则
如果两个数组的后缘维度 (trailing dimension,即从末尾开始算起的维度)的轴长度相符或其中一方的长度为1,则认为它们是广播兼容的.广播会在缺失和(或)长度为1的维度上进行.
怎么理解呢?
可以把维度指的是shape所对应的数字个数那么问题来了:
- shape为(3,3,3)的数组能够和(3,2)的数组进行计算么?
- 不可以,形状不一样
- shape为(3,3,2)的数组能够和(3,2)的数组进行计算么?
- 可以,末尾形状一样(第一块的3行2列和后面的3行2列计算,以此类推)
- 有什么好处呢?
- 举个例子:每列的数据减去列的平均值的结果
numpy常用方法
numpy常用统计方法
Pandas
什么是pandas
一个开源的Python类库:用于数据分析、数据处理、数据可视化
- 高性能
- 容易使用的数据结构
- 容易使用的数据分析工具
很方便和其他类库一起使用:
- numpy:用于数学计算
- scikit-learn:用于机器学习
pandas读取数据
pandas需要先读取表格类型的数据,然后进行分析
| 数据类型 | 说明 | Pandas读取方式 |
|---|---|---|
| csv、tsv、txt | 用逗号分隔、tab分隔的纯文本文件 | pd.read_csv |
| excel | 微软xls或者xlsx文件 | pd.read_excel |
| mysql | 关系型数据库表 | pd.read_sql |
1 | # 导入Pandas |
Pandas数据结构
DataFrame:二维数据,整个表格,多行多列
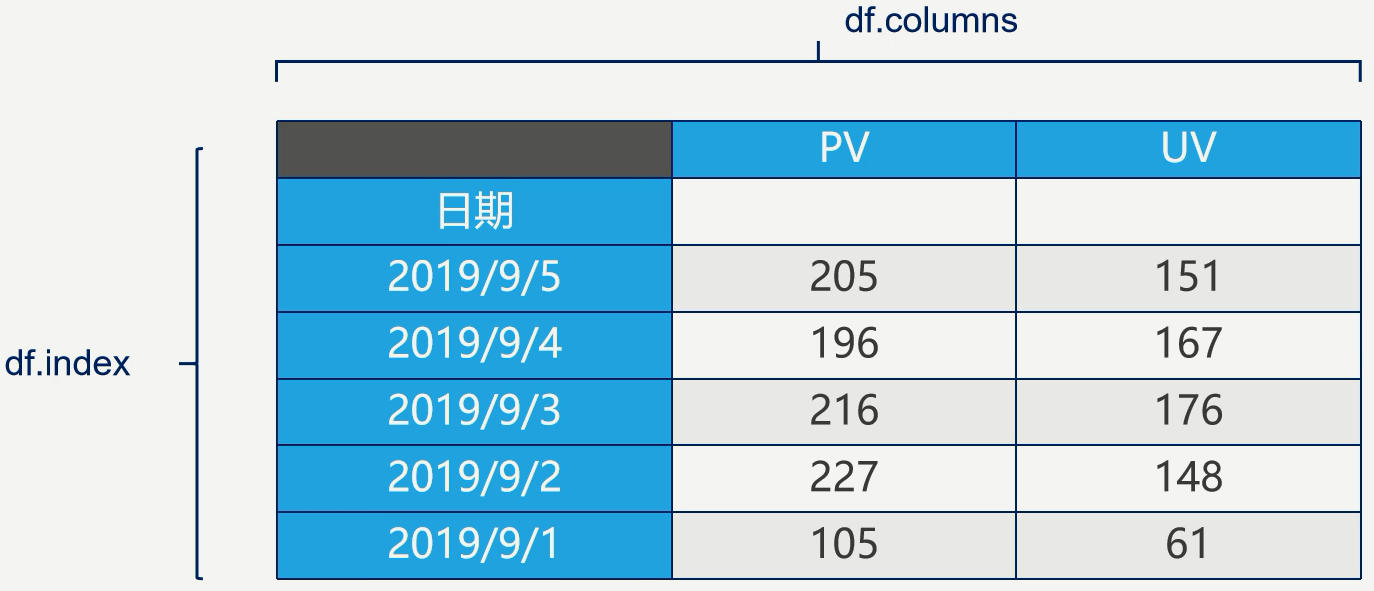
Series:一维数据,一行或一列
- Series
- DataFrame
- 从DataFrame中查询出Series
1 | import pandas as pd |
DataFrame
DataFrame是一个表格型的数据结构
- 每列可以是不同的值类型(数值、字符串、布尔值等)
- 既有行索引index,也有列索引columns
- 可以被看作由Series组成的字典
根据多个字典序列创建dataframe
1 | # 2 DataFrame |
Pandas查询数据的5种方法
按数值、列表、区间、条件、函数五种方法
Pandas查询数据的几种方法
1 | df.loc方法,根据行、列的标签值查询 |
Pandas使用df.loc查询数据的方法
1 | 使用单个label值查询数据 |
注意
- 以上查询方法,既适用于行,也适用于列
- 注意观察降维dataFrame>Series>值
Pandas如何新增数据列
在进行数据分析时,经常需要按照一定条件创建新的数据列,然后进行进一步分析
- 直接赋值
- df.apply方法
- df.assign方法
- 按条件选择分组分别赋值
1 | import pandas as pd |
直接赋值的方法
1 | # 实例:清理温度列,变成数字类型 |
df.apply方法
沿着df的某个轴应用一个函数.传递给函数的对象是个Series对象,其索引是数据帧的索引(axis=0)或数据帧的列(axis=1)
1 | 实例:添加一列温度类型: |
df.assign方法
给数据帧分配新的列.返回一个新对象,其中包含除了新列之外的所有原始列.
1 | # 可以同时添加多个新的列 |
按条件选择分组分别赋值
按条件先选择数据,然后对这部分数据赋值新列
实例:高低温差大于10度,则认为温差大
1 | # 先创建空列(这是第一种创建新列的方法) |
Pandas数据统计函数
- 汇总类统计
- 唯一去重和按值计数
- 相关系数和协方差
汇总类统计
1 | # 一下子提取所有数字列统计结果 |
唯一去重
1 | df['fengxiang'].unique() |
按值计数
1 | df['fengxiang'].value_counts() |
相关系数和协方差
- 协方差:衡量同向反向程度,如果协方差为正,说明X,Y同向变化,协方差越大说明同向程度越高;如果协方差为负,说明X,Y反向运动,协方差越小说明反向程度越高.
- 相关系数:衡量相似程度,当他们相关系数为1时,说明两个变量变化时的正向相似度最大,当相关系数为-1时,说明两个变量变化的反向相似度最大
1 | # 协方差矩阵 |
Pandas缺失值处理
Pandas使用这些函数处理缺失值
- isnull和notnull:检测是否是空值,可用于df和series
- dropna:丢弃、删除缺失值
- axis:删除行还是列,{0 or ‘index’,1or ‘columns’},default 0
- how:如果等于any则任何值都删除,如果等于all则所有值都为空才删除
- inplace:如果为True则修改当前df,否则返回新的df
- fillna: 填充空值
- value:用于填充的值,可以是单个值,或者字典(key是列名,value是值)
- method:等于ffill使用前一个不为空的值填充forword fill;等于bfill使用后一个不为空的值填充backword fill
- axis:按行还是列填充,{0 or ‘index’,1or ‘columns’}
- inplace:如果为True则修改当前df,否则返回新的df
1 | import pandas as pd |
Pandas 的Setting WithCopyWarning 报警复现、原因、解决方案
报警复现
1 | import pandas as pd |
原因
发出警告的代码 df[condition]['wen_cha']=df['bWendu']-df['yWendu']相当于:df.get(condition).set(wen_cha),第一步骤的get发出了报警
链式操作其实是两个步骤,先get后set,get得到的dataframe可能是view也可能是copy,pandas发出警告
核心要诀:pandas的dataframe的修改写操作,只允许在源dataframe上进行,一步到位
解决方法
- 将get+set的两步操作,改成set的一步操作
1 | df.loc[condition,'wendu_cha']=df['bWendu']-df['yWendu'] |
- 如果需要预筛选数据做后续的处理分析,使用copy复制dataframe
1 | df_month3=df[condition].copy() |
注意:pandas不允许筛选子dataframe,再进行修改写入
要么使用.loc实现一个步骤直接修改源dataframe
要么先复制一个子dataframe再执行修改
Pandas数据排序
Series的排序:
Series.sort_values(ascending=True,inplace=False)参数说明:
- ascending:默认为True升序排序,为False降序排序
- inplace:是否修改Series
DataFrame的排序:
DataFrame.sort_values(by,ascending=True,inplace=False)
参数说明:
- by:字符串或者List<字符串>,单列排序或者多列排序
- ascending:bool或者List,升序还是降序,如果是list对应by的多列
- inplace:是否修改原始DataFrame
Series的排序
1 | df['aqi'].sort_values() |
DataFrame的排序
单列排序
1
2df.sort_values(by='aqi')
df.sort_values(by='aqi',ascending=False)多列排序
1
2
3
4
5
6# 按空气质量等级、最高温度排序,默认升序
df.sort_values(by=['aqiLevel','bWendu'])
# 两个字段都是降序
df.sort_values(by=['aqiLevel','bWendu'],ascending=False)
# 分别指定升序和降序
df.sort_values(by=['aqiLevel','bWendu'],ascending=[True,False])
pandas字符串处理
Pandas的字符串处理
- 使用方法:先获取Series的str属性,然后再属性上调用函数
- 只能在字符串列上使用,不能在数字列上使用
- Dataframe上没有str属性和处理方法
- Series.str并不是Python原生字符串,而是自己的一套方法,不过大部分和原生str很相似
演示内容
1 | 1. 获取Series的str属性,然后使用各种字符串处理函数 |
1 | import pandas as pd |
- 获取Series的str属性,使用各种字符串处理函数
1 | df['bWendu'].str |
- 使用str的startswith、contains等得到bool的Series可以做条件查询
1 | condition=df['ymd'].str.startswith('2018-03') |
- 需要多次str处理的链式操作
怎样提取201803这样的数字月份? - 先将日期2018-03-31替换成20180331的形式
- 提取月份字符串201803
1 | # 每次调用函数,都返回一个新Series |
- 使用正则表达式的处理
1 | #添加新列 |
Pandas的axis参数
- axis=0或者’index’:
- 如果是单行操作,就指的是某一行
- 如果是聚合操作,指的是跨行cross rows
- axis=1或者’columns’:
- 如果是单列操作,就指的是某一列
- 如果是聚合操作,指的是跨列cross columns
按哪个axis,就是这个axis要动起来类似被for遍历,其他的axis保持不动
1 | import pandas as pd |
Pandas的索引index
Pandas的索引index的用途
把数据存储与普通的column列也能用于数据查询,那使用index有什么好处?
index的用途总结:
- 更方便的数据查询
- 使用index可以获得性能提升
- 自动的数据对齐功能
- 更多更强大的数据结构支持
Pandas的索引index的用途
1 | import pandas as pd |
使用index会提升查询性能
- 如果index是唯一的,Pandas会使用哈希表优化,查询性能O(1)
- 如果index不是唯一的,但是有序,Pandas会使用二分查找法,查询性能为O(logN)
- 如果index是完全随机的,那么每次查询都要扫描全表,查询性能为O(N)
实验1:完全随机的顺序查询
1 | from sklearn.utils import shuffle |
实验2:将index排序后的查询
1 | df_sorted = df_shuffle.sort_index() |
使用index能自动对其数据
包括series和dataframe
1 | s1=pd.Series([1,2,3],index=list('abc')) |
使用index更多更强大的数据结构支持
很多强大的索引数据结构
- Caregoricalindex,基于分类数据的index,提升性能
- Multiindex,多维索引,用于groupby多维聚合后结果等
- Datetimeindex,时间类型索引,强大的日期和时间的方法支持
Pandas的Merge语法
pandas怎样实现DataFrame的Merge
pandas的Merge,相当于Sql的Join,将不同的表key关联到一个表
merge的语法:
pd.merge(left,right,how='inner',on=None,left_on=None,right_on=None,left_index=False,right_index=False,sort=True,suffixes=('_x','_y'),copy=True,indicator=False,validate=None)
- left,right:要merge的dataframe或者有name的Series
- how: join类型,’left’, ‘right’ , ‘outer’, ‘inner’
- on: join的key,left和right都需要有这个key
- left_on: left的df或者series的key
- right_on: right的df或者seires的key
- left_index,right_index:使用index而不是普通的column做join
- suffixes:两个元素的后缀,如果列有重名,自动添加后缀,默认是(‘_X’,’_Y’)
本次实验提纲
- 电影数据集的join实例
- 理解merge时一对一、一对多、多对多的数量对齐关系
- 理解left join、right join、inner join、 outer join、的区别
- 如果出现非Key的字段重名怎么办
本文由 kill3r 原创,采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




