Redis概述 NoSQL
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS 类型的web2.0纯动态网站已经显得力不从心,出现了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,特别是大数据应用难题
主流的NoSQL产品:
目前缓存的主流技术:Redis、Memcached、mongoDB
缓存的需求
在信息爆炸的今天,数据的存储,对数据的查询都是非常频繁且非常大量的。关系型数据库的就显得力不从心了,扩展性较差,查询简单条件数据的效率较低等缺点,无意是致命的。而NOSQL数据库中的数据之间并无关系,这一特点造就了NOSQL的易扩展性,读写性能高等优势。所以面对大量的数据读写,非关系型数据库相比较于关系型数据库有着巨大的优势。
为什么要使用Nosql? 对数据高并发的读写 海量数据的读写 对数据的高可扩展性 NoSql出现的目地是为解决性能问题所产生的技术 Redis数据库是NOSQL数据库中以key-value存储模式下的一种数据库。
那么Redis数据库为什么又在NOSQL中脱颖而出? Redis支持多种数据类型:string(字符串)hash(哈希)list(列表)set(集合)zset(sorted set:有序集合)。 支持主从复制,读写分离。读写效率大大提升。 数据存储在内存中,可用来做缓存。需要持久化的数据就将其存入硬盘,不需要持久化的数据,可以进行短暂的存储,提高访问速度。 Redis简介及安装
redis下载 linux环境下载:
windows环境下载:
redis官网不支持windows平台的,windows版本是由微软自己建立的一个分支,基于官方的源码上进行编译发布维护,一般比官方版略低
window安装 安装方式一 临时服务
无需要安装,只需要开启服务端和客户端即可
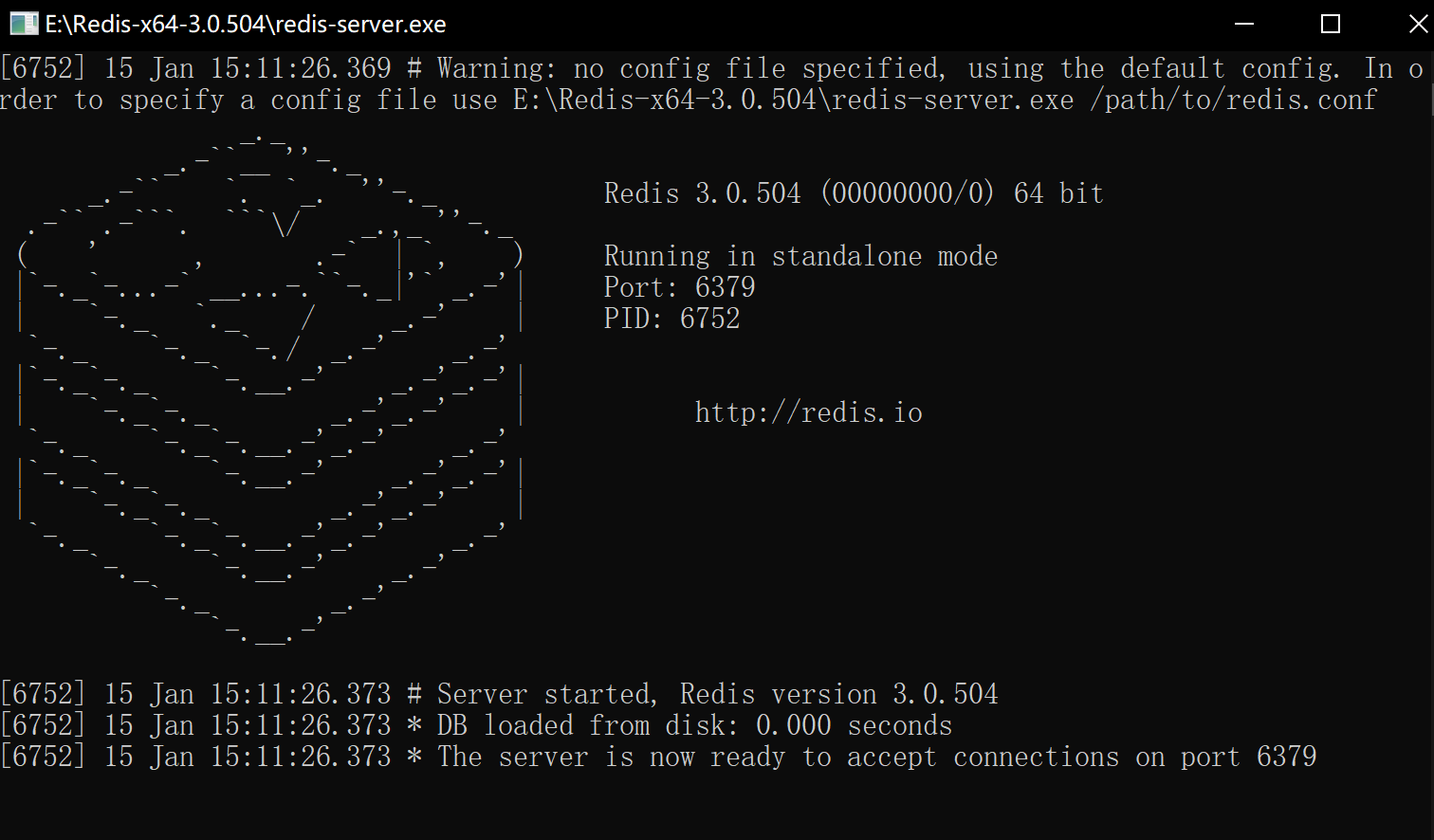
点击``redis-server.exe` 开启服务, 开启后不要关闭,关闭redis服务器就关掉了
点击``redis-cli.exe` 开启客户端
安装方式二 安装到系统服务
直接按装到本机服务中,无需要来回启动
1 2 redis-server --service-install redis.windows.conf --loglevel verbose
1 2 3 4 5 6 7 8 9 10 11 redis-server --service-uninstall 先停掉redis服务器 redis-server --service-start redis-server --service-stop 点击redis-cli.exe redis-cli.exe -h 127.0.0.1 -p 6379
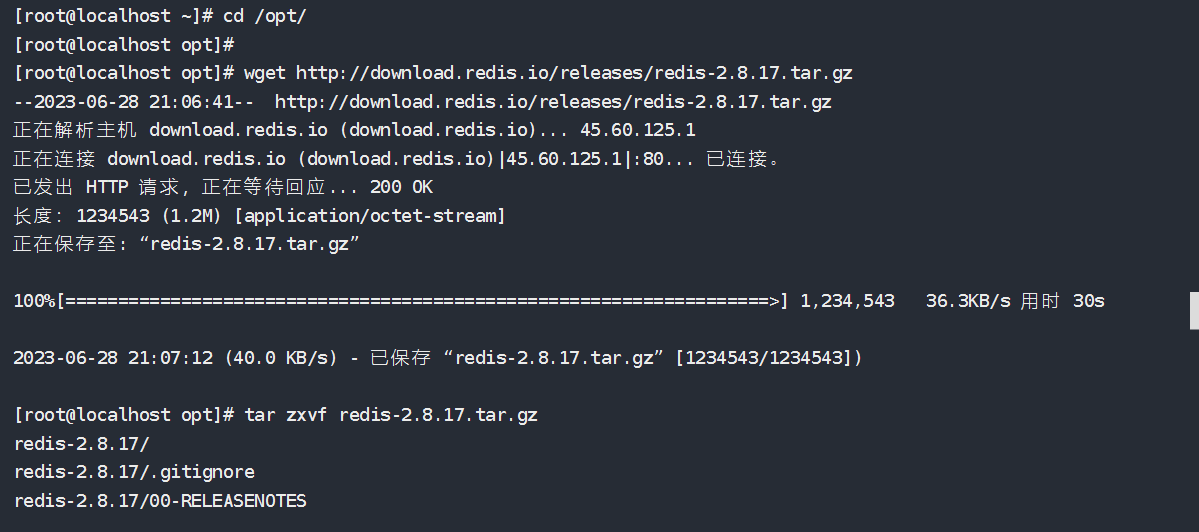
linux安装 1 2 3 4 5 6 7 8 9 10 11 12 cd /optwget http://download.redis.io/releases/redis-2.8.17.tar.gz tar zxvf redis-2.8.17.tar.gz cd redis-2.8.17make cd src/./redis-server
Redis操作 多数据库 redis默认数据库数有16个,0-15号库,默认连接的数据库0号库,通过redis.windows.conf查看
redis不支持自定义数据库名称,redis的多数据库之间不是完全隔离有,flushall命令会清空所有的数据库数据
选择数据库 1 2 3 4 5 6 7 127.0 .0 .1 :6379 > select 1 OK 127.0 .0 .1 :6379 [1 ]> set test abcOK 127.0 .0 .1 :6379 [1 ]> get test"abc" 127.0 .0 .1 :6379 [1 ]>
清空数据库
FLUSHALL – 清空【所有数据库】的所有数据FLUSHDB – 清空【当前】所在数据库的数据
1 2 3 4 5 6 7 8 9 127.0 .0 .1 :6379 > set a 123 OK 127.0 .0 .1 :6379 > get a"123" 127.0 .0 .1 :6379 > flushdb OK 127.0 .0 .1 :6379 > get a (nil) 127.0 .0 .1 :6379 >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 127.0 .0 .1 :6379 > set b 123 OK 127.0 .0 .1 :6379 > get b"123" 127.0 .0 .1 :6379 > select 1 OK 127.0 .0 .1 :6379 [1 ]> set c 123 OK 127.0 .0 .1 :6379 [1 ]> get c"123" 127.0 .0 .1 :6379 [1 ]> flushall OK 127.0 .0 .1 :6379 [1 ]> get c(nil) 127.0 .0 .1 :6379 [1 ]> select 0 OK 127.0 .0 .1 :6379 > get b(nil)
基本命令
keys * – 查看当前所有keyexists key –判断key是否存在,存在返回1,不存在返回0del key – 删除key,成功返回1,失败返回0type key –查看key的数据类型
keys * – 查看当前所有key
1 2 3 4 5 6 7 8 127.0 .0 .1 :6379 > set a 123 OK 127.0 .0 .1 :6379 > set b 321 OK 127.0 .0 .1 :6379 > keys * 1 ) "b"2 ) "a"127.0 .0 .1 :6379 >
exists key –判断key是否存在,存在返回1,不存在返回0
1 2 3 4 5 127.0 .0 .1 :6379 > exists a (integer ) 1 127.0 .0 .1 :6379 > exists c(integer ) 0 127.0 .0 .1 :6379 >
del key – 删除key,成功返回1,失败返回0
1 2 3 4 5 6 7 8 127.0 .0 .1 :6379 > keys * 1 ) "b"2 ) "c"127.0 .0 .1 :6379 > del b (integer ) 1 127.0 .0 .1 :6379 > del a(integer ) 0 127.0 .0 .1 :6379 >
type key –查看key的数据类型
1 2 3 4 5 127.0 .0 .1 :6379 > set a 123 OK 127.0 .0 .1 :6379 > type astring 127.0 .0 .1 :6379 >
1 2 3 4 5 6 7 127.0 .0 .1 :6379 > set k1 aaaOK 127.0 .0 .1 :6379 > set k1 bbbOK 127.0 .0 .1 :6379 > get k1"bbb" 127.0 .0 .1 :6379 >
clear 清屏
五种数据类型
redis存储的是:key,value格式的数据,其中key都是字符串,value有5种不同的数据结构
字符串类型 (String): 这是最基本的类型,一个键可以对应一个字符串值,字符串类型是二进制安全的,可以包含任何数据,如 jpg 图片或者序列化的对象。一个键存储的字符串值最大能达到 512MB。
散列类型 (Hash): Redis hash 是一个键值对集合,它是一个字符串字段和字符串值之间的映射表,适合存储对象。每个 hash 可以存储 2^32 - 1 键值对(40多亿)。
列表类型 (List): Redis 列表是一个简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。它的底层实现是一个双向链表,因此即使列表中有数百万的元素,向列表的两端添加元素也是非常快的。它支持重复元素。
集合类型 (Set): Redis的Set是字符串类型的无序集合。它是通过哈希表实现的,所以添加、删除、查找的复杂度都是O(1)。set 中的最大成员数为2^32 - 1。集合中的元素是唯一的,这意味着同一个集合中不能出现重复的元素。
有序集合类型 (Sorted Set, ZSet):Redis Sorted Sets也是集合,它和 Set 一样也是不允许重复的成员元素,但不同的是每个元素都会关联一个double类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。不仅如此,它还支持按照分数区间和字典区间来获取成员列表。
每种数据结构都有其用途,例如,lists可以用作消息队列,sets可以用来存储无序的集合数据,例如标签、好友关系等,hashes 是存储对象的理想选择,sorted sets可以用来做带有权重的排行榜等。
字符串(string) get、set赋值取值
1 2 3 4 5 6 7 127.0 .0 .1 :6379 > set a 123 OK 127.0 .0 .1 :6379 > get a"123" 127.0 .0 .1 :6379 > get b(nil) 127.0 .0 .1 :6379 >
intcr递增,返回递增后的值 默认+1
1 2 3 4 5 6 127.0 .0 .1 :6379 > incr num(integer ) 1 127.0 .0 .1 :6379 > incr num(integer ) 2 127.0 .0 .1 :6379 > incr num(integer ) 3
incrby增加定制的整数
1 2 3 4 5 6 7 127.0 .0 .1 :6379 > incrby num 2 (integer ) 5 127.0 .0 .1 :6379 > incrby num 2 (integer ) 7 127.0 .0 .1 :6379 > incrby num 2 (integer ) 9 127.0 .0 .1 :6379 >
decr、decrby减少指定的整数
1 2 3 4 5 6 7 8 9 10 11 127.0 .0 .1 :6379 > decr num(integer ) 8 127.0 .0 .1 :6379 > decr num(integer ) 7 127.0 .0 .1 :6379 > decrby num 3 (integer ) 4 127.0 .0 .1 :6379 > decrby num 3 (integer ) 1 127.0 .0 .1 :6379 > decrby num 3 (integer ) -2 127.0 .0 .1 :6379 >
append向键值的末尾追加值 , 返回值是追加后字符串的长度
1 2 3 4 5 6 7 127.0 .0 .1 :6379 > set str helloOK 127.0 .0 .1 :6379 > append str "redis"(integer ) 10 127.0 .0 .1 :6379 > get str"helloredis" 127.0 .0 .1 :6379 >
strlen获取字符串的长度,如何键不存在返回0
1 2 3 4 5 6 7 127.0 .0 .1 :6379 > set str helloOK 127.0 .0 .1 :6379 > strlen str(integer ) 5 127.0 .0 .1 :6379 > strlen a (integer ) 0 127.0 .0 .1 :6379 >
mset、mget 同时设置、获取多个键值
1 2 3 4 5 6 7 8 127.0 .0 .1 :6379 > mset k1 v1 k2 v2 k3 v3OK 127.0 .0 .1 :6379 > get k1"v1" 127.0 .0 .1 :6379 > mget k2 k31 ) "v2"2 ) "v3"127.0 .0 .1 :6379 >
del 指定删除键,如果不存返回0
1 2 3 4 5 6 127.0 .0 .1 :6379 > set m 111 OK 127.0 .0 .1 :6379 > del m(integer ) 1 127.0 .0 .1 :6379 > del n(integer ) 0
哈希类型(hash) 哈希类型 hash, map类型
存储 :hset key field value
1 2 3 4 127.0 .0 .1 :6379 > hset myhash username zhangsan(integer ) 1 127.0 .0 .1 :6379 > hset myhash password asd123(integer ) 1
获取:
hget key field: 获取指定的field对应的值
hgetall key:获取所有的field和value
1 2 3 4 5 6 7 8 9 10 127.0 .0 .1 :6379 > hget myhash username"zhangsan" 127.0 .0 .1 :6379 > hget myhash password"asd123" 127.0 .0 .1 :6379 > hgetall myhash1 ) "username"2 ) "zhangsan"3 ) "password"4 ) "asd123"127.0 .0 .1 :6379 >
删除: hdel key field
1 2 3 4 5 6 127.0 .0 .1 :6379 > hdel myhash username(integer ) 1 127.0 .0 .1 :6379 > hgetall myhash1 ) "password"2 ) "123"127.0 .0 .1 :6379 >>
列表类型(list) 列表类型list : linkedlist格式, 支持重复元素
特点:单键多值
添加:
可以添加一个元素到列表的头部(左边)或者尾部(右边)对两端的操作性能都比较高,查询效率比较低
lpush key value: 将元素加入列表(左边)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 127.0 .0 .1 :6379 > lpush k1 a(integer ) 1 127.0 .0 .1 :6379 > lpush k1 b(integer ) 2 127.0 .0 .1 :6379 > lpush k1 c(integer ) 3 127.0 .0 .1 :6379 > 127.0 .0 .1 :6379 > lpush k1 a a b b (integer ) 4 127.0 .0 .1 :6379 > flushdb 127.0 .0 .1 :6379 > lpush k1 a b c 127.0 .0 .1 :6379 > lindex k1 0 "c" 127.0 .0 .1 :6379 > lindex k1 1 "b" 127.0 .0 .1 :6379 > lindex k1 2 "a" 127.0 .0 .1 :6379 > lrange k1 0 -1 1 ) "c" 2 ) "b" 3 ) "a" 127.0 .0 .1 :6379 >
rpush key value:将元素加入列表(右边)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 127.0 .0 .1 :6379 > rpush k2 v1 v2 v3 (integer ) 3 127.0 .0 .1 :6379 > lindex k2 0 "v1" 127.0 .0 .1 :6379 > lindex k2 1 "v2" 127.0 .0 .1 :6379 > lindex k2 2 "v3" 127.0 .0 .1 :6379 > lrange k2 0 -1 1 ) "v1" 2 ) "v2" 3 ) "v3" 127.0 .0 .1 :6379 > 127.0 .0 .1 :6379 > llen k2 (integer ) 3
获取 :返回列表中指定区间内的元素,区间以偏移量start和end指定。其中
0表示列表的第一个元素,
1表示列表的第 二个元素,
依次类推( 索引0..end )。
你也可以使用负数,
-1表示最后一个元素,
-2表示倒数第二个元素,
依次类推。
lrange key start end 范围获取
lindex key index 根据索引获取
llen key 获取长度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 127.0 .0 .1 :6379 > lpush k1 a b c(integer ) 3 127.0 .0 .1 :6379 > lindex k1 0 "c" 127.0 .0 .1 :6379 > lindex k1 1 "b" 127.0 .0 .1 :6379 > lindex k1 2 "a" 127.0 .0 .1 :6379 > lrange k1 0 -1 1 ) "c"2 ) "b"3 ) "a"127.0 .0 .1 :6379 > lrange k1 0 -2 1 ) "c"2 ) "b"127.0 .0 .1 :6379 > 127.0 .0 .1 :6379 > llen k1 (integer ) 3 127.0 .0 .1 :6379 >
删除 :
lpop key: 删除列表最左边的元素,并将元素返回
rpop key: 删除列表最右边的元素,并将元素返回
1 2 3 4 5 6 7 8 9 10 11 12 13 127.0 .0 .1 :6379 > lpush k1 a b c 127.0 .0 .1 :6379 > lrange k1 0 -1 1 ) "c"2 ) "b"3 ) "a"127.0 .0 .1 :6379 > lpop k1 "c" 127.0 .0 .1 :6379 > lpop k1"b" 127.0 .0 .1 :6379 > lpop k1"a" 127.0 .0 .1 :6379 > keys * (empty array )
集合类型(set) 集合类型set , 不允许重复元素, 无序, 与java中的HashSet内部实现是一样的
存储 :sadd key value
1 2 3 4 5 6 7 8 9 10 11 127.0 .0 .1 :6379 > sadd myset a (integer ) 1 127.0 .0 .1 :6379 > sadd myset a (integer ) 0 127.0 .0 .1 :6379 > scard myset (integer ) 1 127.0 .0 .1 :6379 > smembers myset 1 ) "a"127.0 .0 .1 :6379 > flushdb127.0 .0 .1 :6379 > sadd myset a a b c (integer ) 3
获取 :smembers key:获取set集合中所有元素
1 2 3 4 5 6 7 8 127.0 .0 .1 :6379 > sadd myset a b c(integer ) 3 127.0 .0 .1 :6379 > smembers myset1 ) "b"2 ) "c"3 ) "a"127.0 .0 .1 :6379 > smembers myset2 (empty list or set )
随机操作 :srandmember key随机查询set中的元素; spop key随机删除set中的元素;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 127.0 .0 .1 :6379 > srandmember myset"a" 127.0 .0 .1 :6379 > srandmember myset"c" 127.0 .0 .1 :6379 > srandmember myset"a" 127.0 .0 .1 :6379 > spop myset "b" 127.0 .0 .1 :6379 > spop myset"d" 127.0 .0 .1 :6379 > smembers myset 1 ) "c"2 ) "a"127.0 .0 .1 :6379 >
删除 :srem key value:删除set集合中的某个元素
1 2 3 4 5 6 7 8 9 127.0 .0 .1 :6379 > srem myset c (integer ) 1 127.0 .0 .1 :6379 > smembers myset1 ) "b"2 ) "a"127.0 .0 .1 :6379 > srem myset a b (integer ) 2 127.0 .0 .1 :6379 > smembers myset(empty array )
有序集合(zset) 有序集合类型 sorted set, 不允许重复元素,且元素有顺序; 每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
存储 :zadd key score value
1 2 3 4 5 6 7 8 9 10 127.0 .0 .1 :6379 > zadd mysort 80 jack(integer ) 1 127.0 .0 .1 :6379 > zadd mysort 80 jack (integer ) 0 127.0 .0 .1 :6379 > zadd mysort 60 lisi(integer ) 1 127.0 .0 .1 :6379 > zadd mysort 20 zhangsan(integer ) 1 127.0 .0 .1 :6379 > flushdb127.0 .0 .1 :6379 > zadd mysort 80 jack 60 lisi 20 zhangsan
获取 :zrange key start end [withscores]
1 2 3 4 5 6 7 8 9 10 11 12 13 127.0 .0 .1 :6379 > zrange mysort 0 -1 1 ) "zhangsan"2 ) "lisi"3 ) "jack"127.0 .0 .1 :6379 > 127.0 .0 .1 :6379 > zrange mysort 0 -1 withscores 1 ) "zhangsan"2 ) "20"3 ) "lisi"4 ) "60"5 ) "jack"6 ) "80"127.0 .0 .1 :6379 >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 127.0 .0 .1 :6379 > flushdb 127.0 .0 .1 :6379 > zadd mysort 100 a 200 b 300 c 400 d 500 e(integer ) 5 127.0 .0 .1 :6379 > zrange mysort 0 -1 1 ) "a"2 ) "b"3 ) "c"4 ) "d"5 ) "e"127.0 .0 .1 :6379 > zrangebyscore mysort 100 300 1 ) "a"2 ) "b"3 ) "c"127.0 .0 .1 :6379 > zrangebyscore mysort 100 300 withscores1 ) "a"2 ) "100"3 ) "b"4 ) "200"5 ) "c"6 ) "300"127.0 .0 .1 :6379 >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 127.0 .0 .1 :6379 > zrevrangebyscore mysort 500 200 1 ) "e"2 ) "d"3 ) "c"4 ) "b"127.0 .0 .1 :6379 > zrevrangebyscore mysort 500 200 withscores1 ) "e"2 ) "500"3 ) "d"4 ) "400"5 ) "c"6 ) "300"7 ) "b"8 ) "200"127.0 .0 .1 :6379 >
1 2 3 4 127.0 .0 .1 :6379 > zcount mysort 100 300 (integer ) 3 127.0 .0 .1 :6379 >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 127.0 .0 .1 :6379 > zrank mysort a(integer ) 0 127.0 .0 .1 :6379 > zrank mysort b(integer ) 1 127.0 .0 .1 :6379 > zrange mysort 0 -1 withscores 1 ) "a" 2 ) "100" 3 ) "b" 4 ) "200" 5 ) "c" 6 ) "300" 7 ) "d" 8 ) "400" 9 ) "e" 10 ) "500"
删除 :zrem key value
1 2 3 4 127.0 .0 .1 :6379 > zrem mysort b(integer ) 1 127.0 .0 .1 :6379 > zrem mysort a c(integer ) 2
Redis生存时间 redis在实际应用中更多是用作缓存,解而缓存的数据一般都需要设置生存时间的 即:到期后数据销毁
设置生存时间 设置生存时间 expire key seconds
TTL 返回值:
大于0:剩余生存时间,单位为秒
负数: 数据已经被删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 127.0 .0 .1 :6379 > set k1 abcOK 127.0 .0 .1 :6379 > expire k1 10 (integer ) 1 127.0 .0 .1 :6379 > ttl k1 (integer ) 3 127.0 .0 .1 :6379 > ttl k1(integer ) 2 127.0 .0 .1 :6379 > ttl k1(integer ) 1 127.0 .0 .1 :6379 > ttl k1 (integer ) -2 127.0 .0 .1 :6379 > get k1 (nil)
清除生存时间 清除生存时间 persist key
1 2 3 4 5 6 7 8 9 10 11 12 13 14 127.0 .0 .1 :6379 > set k1 123 OK 127.0 .0 .1 :6379 > expire k1 100 (integer ) 1 127.0 .0 .1 :6379 > ttl k1 (integer ) 51 127.0 .0 .1 :6379 > ttl k1(integer ) 50 127.0 .0 .1 :6379 > persist k1 (integer ) 1 127.0 .0 .1 :6379 > ttl k1 (integer ) -1 127.0 .0 .1 :6379 > get k1"123"
设置单位为毫秒 设置单为毫秒 pexpire key milliseconds
1 2 3 4 5 6 7 8 9 10 127.0 .0 .1 :6379 > set k1 123 OK 127.0 .0 .1 :6379 > pexpire k1 10000 (integer ) 1 127.0 .0 .1 :6379 > ttl k1(integer ) 7 127.0 .0 .1 :6379 > ttl k1(integer ) 6 127.0 .0 .1 :6379 > ttl k1(integer ) 5